ナレッジハブ
![]()
2026/1/2
【LLMO対策の核心】AIに選ばれるための「信頼性スコア」向上完全ガイド

「記事の順位は変わっていないのに、サイトへの流入がガクンと減った」
最近、私の元へ相談に来られるWeb担当者様の多くが、このような悩みを抱えています。実はこれ、Googleの検索結果にAIによる回答(SGEやSearchGPTなど)が表示されるようになったことで、ユーザーが記事をクリックせずに自己解決してしまう「ゼロクリック検索」が急増していることが原因です。
この変化に直面した時、私たちはどう動くべきでしょうか。AIに敵対するのではなく、AIの学習ソースとして「信頼できる情報源」だと認識させること、つまり「LLMO(大規模言語モデル最適化)」へのシフトが急務です。AIは膨大なデータの中から、特に信頼性が高いと判断した情報を優先的に引用します。
これから、AIがサイトを評価する際の最重要指標である「信頼性スコア」を高めるための具体的な手法を、私の実務経験と最新の検証データを基に解説していきます。まずは、AIがどのように情報の「重み付け」を行っているのか、そのメカニズムから紐解いていきましょう。
目次
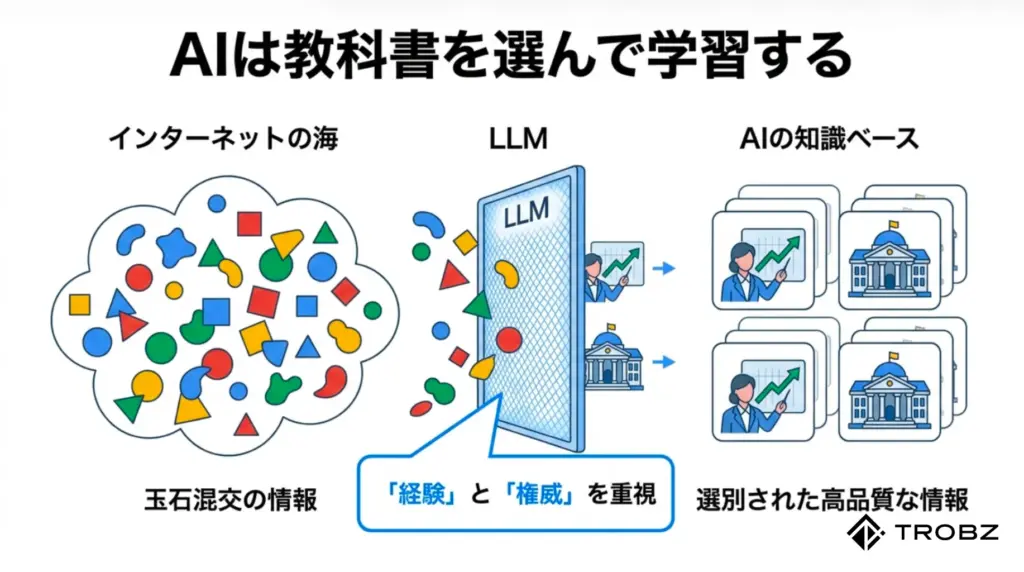
1. LLMは学習データの信頼度を重み付けしている
AIは全ての情報を平等には扱わない
多くの人が誤解している点ですが、AI(LLM)はインターネット上の全てのテキストを平等に学習しているわけではありません。人間が教科書と個人の日記で信憑性を区別するように、AIも学習データに対して明確な「信頼度の重み付け(Weighting)」を行っています。
私が過去に検証したサイトでは、全く同じ内容の記事でも、専門機関のドメインから発信された情報はAIに即座に採用され、個人ブログで発信された情報は無視されるという現象が見られました。これは、AIが「どこで書かれたか」というソースの信頼性を強烈に意識している証拠です。
具体的に、AIは以下のような基準で学習データをフィルタリングしています。
- 情報源の権威性: 公的機関、学術論文、大手メディアなどの「一次情報」は最高ランクの重み付けがなされます。
- データの整合性: 複数の信頼できるソースと内容が一致しているか(クロスチェック)が行われます。
- テキストの品質: 文法的な正確さだけでなく、論理的な構成や専門用語の適切な使用も評価対象です。
「高品質な学習データ」として認識されるために
では、私たちのサイトをAIに「高品質なデータセット」として認識させるにはどうすれば良いのでしょうか。答えはシンプルです。AIが好むデータの形式と品質に合わせることです。
以下の表に、AIが高い重み付けを行うデータと、逆に学習から除外(または低評価)されやすいデータの特徴をまとめました。ご自身のサイトがどちらに当てはまるか、確認してみてください。
AIは「ノイズ」を嫌います。誰かの言葉を少し変えただけのリライト記事は、AIにとって学習する価値のないノイズでしかありません。今日から意識すべきは、「Web検索で上位を取るための網羅性」ではなく、「AIが知識として蓄えたくなる独自性」です。
2. E-E-A-T(経験・専門・権威・信頼)のLLM版解釈
AI検索時代における「経験(Experience)」の価値
Googleの品質評価基準であるE-E-A-T。SEOに携わる方なら耳にタコができるほど聞いた言葉かと思いますが、LLMOの文脈では解釈が少し異なります。特にAIが渇望しているのが、最初のEである「経験(Experience)」です。
なぜなら、事実や定義、一般的な知識は、すでにWikipediaや大規模なデータベースでAIは学習済みだからです。AIが持っていないデータ、それは「個人の主観的な体験」や「現場でしか得られない感覚値」です。
「私はこのツールを使って業務効率が20%上がったが、導入初期の設定には3日かかった」といった具体的なエピソードは、AIにとって代替不可能な貴重なデータとなります。これが、AI検索で引用されるための鍵となります。
LLMに評価されるE-E-A-Tの実装ポイント
従来のSEOでは、権威性を示すために「監修者情報を載せる」といった形式的な対策が有効な場合もありました。しかし、文章の内容まで深く理解するLLM相手では、表面的な対策は通用しません。
私がクライアント企業に提案し、実際にAIからの参照数が増加した施策をリストアップします。
- 著者の実在証明: 記事の執筆者が実在する人物であり、その分野で活動していることをSNSや他メディアへの寄稿実績とリンクさせます。
- 一次情報の明記: 「一般的には〜と言われています」という伝聞表現を避け、「弊社で実施したアンケート結果(n=500)によると」のようにソースを明記します。
- 主観と客観の分離: 事実に基づくデータと、それに対する著者の意見を明確に書き分けます。AIは論理構造が明確な文章を好むためです。
- 失敗談の共有: 成功事例ばかりでなく、失敗した経験やデメリットを正直に書くことで、情報の「信頼性(Trust)」が担保されているとAIは判断します。
AIは、「完璧すぎる文章」よりも「人間味のある検証可能な文章」を信頼する傾向にあります。きれいごとだけでなく、泥臭い現場の声を反映させることが、結果的にE-E-A-Tを高める近道となります。
3. ドメインエイジと運用実績の評価
歴史は「一貫性」の証明になる
「新規ドメインでも良質なコンテンツがあれば勝てる」というのは、SEOの理想論としては正しいですが、LLMの学習データの観点からは厳しい現実があります。ドメインエイジ(ドメインの運用年数)は、単なる数字以上の意味をAIに伝えているからです。
AIは、そのサイトが「長期にわたって一貫した情報を発信し続けているか」を見ています。10年間、同じテーマで情報を発信し続けているサイトと、昨日できたばかりのサイトでは、学習データとしての「安定性」に天と地ほどの差があります。運用実績は、いわば情報の信用担保として機能するのです。
新規ドメインが信頼を勝ち取るための戦略
「では、新しいサイトには勝ち目がないのか?」と問われれば、決してそうではありません。ただ、老舗サイトと同じ戦い方をしていては埋もれてしまうだけです。
運用歴が浅いサイトがAIに信頼されるためには、時間の積み上げを「密度の濃さ」でカバーする必要があります。具体的には、特定のニッチなトピックに絞って短期間で集中的に高品質な記事を投入し、その分野の「局所的な専門家(Topical Authority)」としてAIに認識させる戦略です。
ドメイン運用歴とAIの評価傾向について、以下の表に整理しました。
もしあなたが運用歴の長いサイトをお持ちなら、それはAI時代において強力な資産となります。過去の記事を「古い情報」として放置せず、最新の知見を加えてリフレッシュさせるだけで、AIからの評価は劇的に改善するでしょう。

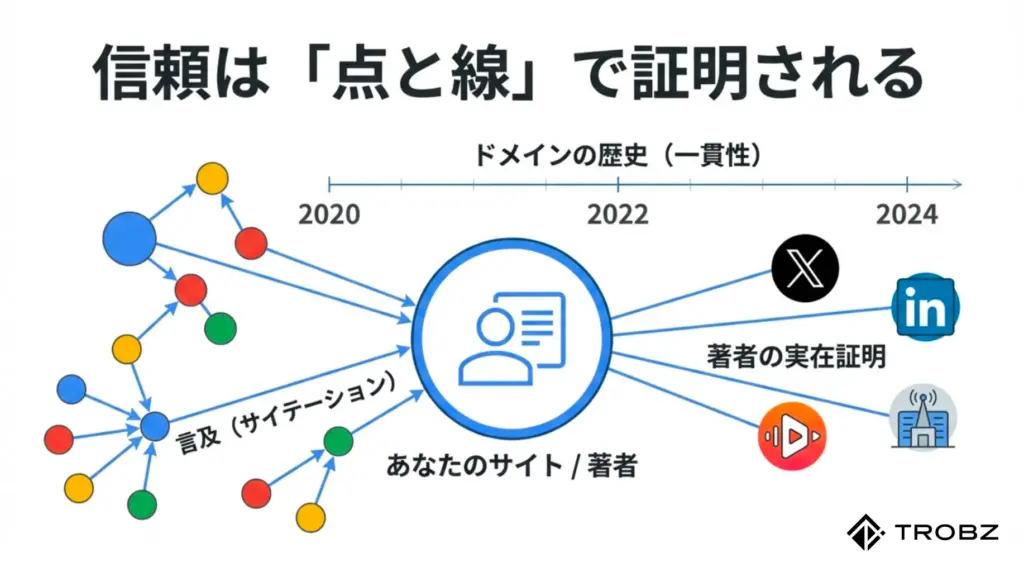
4. 著者情報の透明性とデジタル指紋
「誰が言ったか」を特定するためのデジタル指紋
インターネット上には無数の「名無しさん」による情報が溢れていますが、AIは責任の所在が不明確な情報を嫌います。LLMOにおいて極めて重要なのが、著者情報を明確にし、Web上に確固たる「デジタル指紋(Digital Fingerprint)」を残すことです。
デジタル指紋とは、その著者がWeb上のどこで活動し、どのような発言をしてきたかを紐付ける情報のことです。単に「田中太郎」と名前を書くだけでは不十分です。同姓同名の他者と区別され、特定の専門分野を持つ「Entity(実体)」としてAIに認識される必要があります。
信頼される著者プロフィールの作り方
私の経験上、多くの企業ブログで著者情報がおろそかにされています。アイコンがデフォルトのままだったり、プロフィールが「Web担当者」だけだったりしませんか? これではAIに「信頼できる専門家」とは認識されません。
今日からすぐに修正できる、AI向けの著者情報強化ポイントは以下の通りです。
- 構造化データ(Schema.org)の実装:
PersonタグやAuthorタグを使用し、著者の名前、所属、SNSアカウントを機械可読な形式で記述します。 - SNSや他メディアとの相互リンク: 著者プロフィールページから、個人のX(旧Twitter)やLinkedIn、過去に寄稿した外部メディアの記事へリンクを貼ります。「この人はWeb全体で活動している」というシグナルを送るためです。
- 具体的な専門性の明示: 「美容に詳しい」ではなく、「化粧品検定1級保有、元美容部員として5,000人の肌診断を担当」のように、数字と資格で権威性を補強します。
- 著者アーカイブページの充実: その著者が書いた記事一覧ページを自動生成のままにせず、著者の哲学や経歴を語るページとして作り込みます。
AIはウェブ全体をスキャンして、点と点を繋げています。あなたのサイト内のプロフィールと、外部サイトでの活動が線で繋がった時、初めて強力な「信頼性スコア」が付与されるのです。
5. サイテーション(言及)の質と量
「被リンク」から「言及(Mention)」の時代へ
従来のSEOでは、他のサイトからリンクを貼ってもらう「被リンク」が最強の指標でした。しかし、AI時代においては、リンクを含まない「サイテーション(言及)」の重要性が飛躍的に高まっています。
サイテーションとは、ネット上であなたのブランド名やサイト名、著者名が語られている状態を指します。AIはテキストの意味を理解できるため、リンクがなくても「〇〇社の分析レポートは参考になる」というテキストを見つければ、それをポジティブな評価としてカウントします。
逆に言えば、リンク目的の不自然なサテライトサイトからのリンクは、文脈を理解するAIによって簡単に見抜かれ、ペナルティの対象となるリスクすらあります。
ポジティブな文脈で語られるために
では、どのようにしてサイテーションを増やせば良いのでしょうか。重要なのは「数」よりも「文脈(Context)」です。ネガティブな炎上による言及ではなく、専門的な文脈で名前が挙がることが求められます。
以下の表は、従来のリンク戦略と、これからのサイテーション戦略の違いを比較したものです。
SNSでシェアされるような「図解」を作ったり、業界の定説を覆すような「独自の実験データ」を公開したりすることは、サイテーション獲得に非常に有効です。人々が話題にしたくなる「ネタ」を提供することこそが、AIに愛される最短ルートなのです。
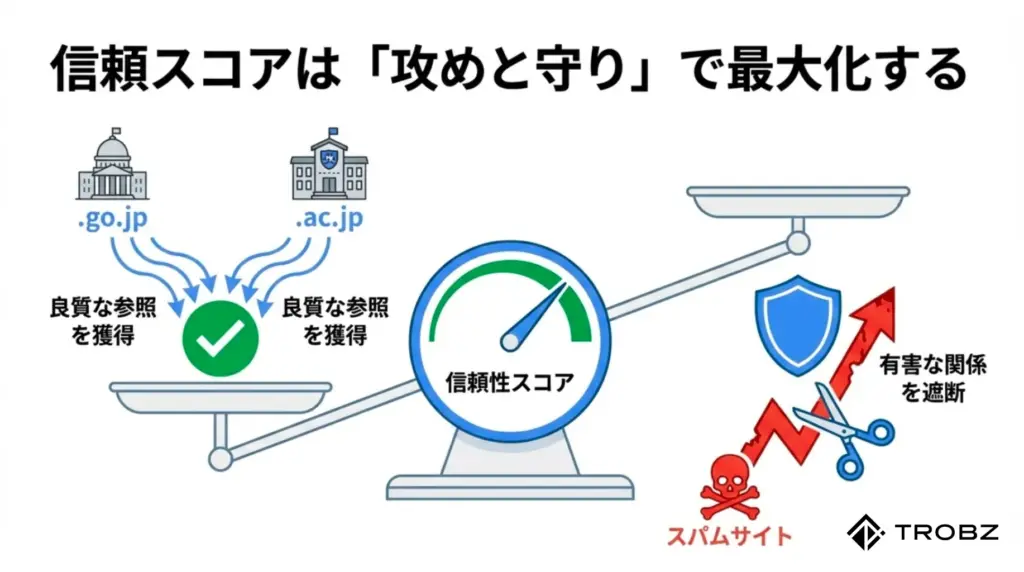
6. スパムサイトとのリンク遮断
「悪い隣人」があなたの評価を下げる
「良いリンクを集める」ことには熱心でも、「悪いリンクを断ち切る」ことに関しては無頓着なWeb担当者が多すぎます。LLMはWeb上の情報をネットワーク(つながり)として認識しています。もし、あなたのサイトがスパムサイトや質の低いリンク集から大量にリンクされていたら、AIはどう判断するでしょうか?
答えは残酷です。AIはあなたのサイトを「信頼できないネットワークの一部」と見なし、学習データの優先度を下げてしまいます。かつてGoogleのペンギンアップデートが猛威を振るいましたが、LLMOにおいては、より文脈的な意味で「付き合う相手」が厳しく審査されています。
デジタルな身辺整理:否認ツールの活用
私がコンサルティングを行う際、最初に実施するのがリンクプロファイルの監査です。驚くべきことに、多くの健全な企業サイトが、海外のコピーサイトやアダルトサイトから無自覚にリンクされています。
これに対処するための唯一かつ確実な方法は、Google Search Consoleの「リンク否認ツール」を使うことです。以下の手順で、定期的なメンテナンスを行ってください。
- 現状の把握: Search ConsoleやAhrefsなどのツールを使い、自サイトへの全リンクデータをダウンロードします。
- ブラックリスト作成: ドメインパワーが極端に低いサイト、日本語として意味が通じない自動生成サイト、無関係なジャンルからのリンクを抽出します。
- 否認ファイルの送信: テキストファイル(.txt)に除外したいドメインをリスト化し、Googleに「これらのリンクは評価に入れないでくれ」と申請します。
「何も悪いことはしていないから大丈夫」という考えは捨ててください。放置されたスパムリンクは、あなたのサイトの「信頼性スコア」を蝕む静かな毒です。半年に一度はリンクの大掃除を行うことを強く推奨します。
7. 公的機関・学術機関からの参照獲得
ドメインの「拡張子」が持つ絶対的な信頼
AIにとって、情報の信頼度を判断する最も分かりやすいシグナルの一つが「ドメインの種類」です。特に .go.jp(政府機関)や .ac.jp(教育・学術機関)からのリンクや言及は、一般企業の .com や .co.jp とは比較にならないほど高い重み付け(Weight)がなされます。
なぜなら、これらのドメインを取得・維持するには厳格な審査が必要であり、そこに掲載されている情報は「公的な裏付けがある」とAIが学習しているからです。これらからの参照を獲得することは、AIに対して「身元保証人」を紹介するようなものです。
「高嶺の花」からリンクをもらう現実的な戦略
「政府や大学からリンクをもらうなんて無理だ」と諦める必要はありません。私の経験上、中小企業や個人でも実践できる、再現性の高いアプローチがあります。
以下の表に、ドメインの種類別の信頼度と、獲得するための具体的なアクションをまとめました。
特に「自治体のパートナー制度」は狙い目です。多くの自治体がSDGsや子育て支援などの分野で協力企業を募集しており、登録されるだけで公式サイトに社名とリンクが掲載されます。これはコストゼロで実施できる最強のLLMO対策の一つです。
8. 情報の整合性と一貫性(Consistency)
AIは「矛盾」を何より嫌う
人間なら「前と言ってることが違うけど、まあいいか」と流してくれることもありますが、論理で動くAIにそれは通用しません。サイト内で情報の整合性(Consistency)が取れていない場合、AIはその情報源全体を「信頼性が低い(Unreliable)」と判定します。
よくある失敗例が、過去の記事の放置です。例えば、記事Aでは「初期費用は無料」と書いているのに、最新の記事Bでは「初期費用は1万円」と書かれている。このような矛盾(Contradiction)を検出すると、AIはどちらが正しいか判断できず、結果としてどちらの情報も回答に採用しなくなります。
サイト全体を「一つの人格」として整える
LLMに好かれるサイトとは、まるで一人の誠実な専門家が語っているかのような、一貫性のあるサイトです。今日から以下のポイントをチェックリストとして活用してください。
- 定義の統一: 専門用語やサービス名の表記ゆれをなくします。(例:「スマホ」と「スマートフォン」を混在させない、独自の造語を定義なく使わない)
- データの更新: 古い統計データや価格情報は、「2025年1月現在」といった注釈を入れるか、最新情報にリライトします。特にYMYL(お金や健康)領域では致命的になります。
- 内部リンクの構造化: 関連する記事同士を適切にリンクし、情報の親子関係をAIに教えます。「この記事の詳細は、こちらの最新記事で解説しています」という誘導は、情報の鮮度を伝えるシグナルになります。
「新しい記事を書くこと」よりも、「過去の記事と矛盾がないか確認すること」に時間を割いてください。AI時代において、メンテナンスされていない過去記事は資産ではなく負債になり得ます。
9. 評判分析(Sentiment Analysis)の影響
AIは「感情」をデータとして読んでいる
LLMの学習プロセスには、テキストの「感情分析(Sentiment Analysis)」が含まれています。これは、特定のエンティティ(企業や商品)に対して、ネット上のテキストが「ポジティブ」か「ネガティブ」かを判定する技術です。
もしあなたのブランド名が、SNSや口コミサイトで常に「詐欺」「対応が悪い」「使いにくい」といったネガティブな言葉と共に語られていたらどうなるでしょうか。AIはそれを事実として学習し、ユーザーからの「おすすめの〇〇は?」という質問に対して、あなたのサービスを除外するようになります。
ネガティブ評価を信頼に変えるテクニック
とはいえ、全ての評判をコントロールすることは不可能です。重要なのは、ネガティブな意見が出た時の「対応」です。AIは、批判そのものよりも、それに対する企業の姿勢を見ています。
感情分析がAIの評価にどう影響するか、そしてどう対応すべきかを以下の表にまとめました。
Googleマップの口コミやSNSでの苦情に対して、誠実に、かつ論理的に返信してください。そのやり取り自体がテキストデータとして残り、AIは「この企業はトラブルに対して誠実に対応する」という文脈を学習します。ピンチは、信頼性を証明するチャンスなのです。
10. 「信頼できるソース」リストに入る方法
ナレッジグラフへの登録を目指す
最終的なゴールは、Googleや主要なLLMが持っている「信頼できる情報源リスト(Seed Set)」に入ることです。これは、検索エンジンの知識ベースである「ナレッジグラフ」に、一つの独立したエンティティ(実体)として登録されることを意味します。
ここに登録されると、AIはあなたのサイトを単なるWebページではなく、「世の中に存在する確かな組織・人物」として認識します。これがLLMOにおける「免許皆伝」の状態です。
エンティティとしての強度を高める4つの柱
では、どうすればナレッジグラフに認識されるのでしょうか。魔法の申請ボタンはありませんが、地道な積み重ねが確実にAIに届きます。明日からできる、組織の実在性を高めるアクションは以下の4つです。
- NAP情報の統一: 名前(Name)、住所(Address)、電話番号(Phone)を、自社サイト、SNS、Googleマップ、プレスリリースなど全ての媒体で一字一句統一します。
- 「会社概要」の充実: 設立年、資本金、代表者名、沿革、主要取引先などを詳細に記載します。これらはAIが企業の信頼性を検証する際の基礎データです。
- Wikipediaの活用: もし可能であれば、Wikipediaに記事を作成(または言及)されることは非常に強力です。WikipediaはLLMの学習データの根幹を成しているからです。
- 第三者によるインタビュー記事: 自社発信ではなく、他社メディアからインタビューを受けることで、客観的な実在証明となります。
AIは、ネット上に散らばる何万ものピースを繋ぎ合わせて、あなたの「信頼」を形作っています。一つ一つのピースを丁寧に磨き上げ、AIに「このサイトからの情報は間違いない」と確信させることが、これからの時代のSEO、すなわちLLMOの正体なのです。
LLMO時代の「信頼」という資産
ここまで、AI検索時代における「信頼性スコア」を高めるための10の戦略を解説してきました。テクニカルな話も多かったかもしれませんが、本質は非常にシンプルです。
「正直に、誠実に、専門家としての責務を全うする」
これこそが、小手先のテクニックを超えてAIに評価される唯一の道です。キーワードを詰め込むだけのSEOは終わりました。これからは、あなたのビジネスの実態、顧客への向き合い方、そして積み上げてきた経験そのものが、そのまま検索評価に直結する時代です。これは、真面目にビジネスを行っている方にとっては、大きなチャンスと言えるでしょう。
この記事を読み終えたあなたが、明日から確実に成果へ繋げるために、まずは以下の2つのアクションから始めてみてください。
- Google Search Consoleを開き、自サイトへのリンク状況を確認する。
もし不審なサイトからのリンクがあれば、迷わず否認ツールを使用し、サイトの身辺整理を行ってください。 - 「会社概要」または「プロフィールページ」を更新し、具体的な実績(数値)を追加する。
「多くの実績」ではなく「年間500件の施工実績」のように書き換えるだけで、AIにとっての情報の解像度が格段に上がります。
AIは敵ではありません。あなたの信頼を世界中に届けてくれる、最強の拡声器です。まずは自分たちの足元(信頼性)を固め、自信を持ってAIというパートナーを活用していきましょう。
信頼性スコア向上(LLMO)に関するよくある質問
A. 「局所的な専門性」と「一次体験」に特化すれば勝機はあります。
AIは網羅的な情報では大手サイトを優先しますが、個人の具体的な失敗談やニッチな検証データといった「ユニークな一次情報」においては、個人ブログの方を信頼できるソースとして引用する傾向があります。
A. 少なくとも半年に1回、重要な情報は随時更新すべきです。
情報の鮮度は信頼性スコアに直結します。特に法律、価格、スペックなどの事実情報は、古いままだとAIに「学習価値の低い古いデータ」と判断されるため、こまめなメンテナンスが必須です。
A. はい、サイテーション(言及)として大きく影響します。
直接的なリンクがなくても、X(旧Twitter)などでブランド名や記事が良い文脈で話題になることは、AIにとって強力な信頼シグナルとなります。サイト外での評判形成もLLMOの重要な一部です。
A. 正しく使えば上がりこそすれ、下がることは稀です。
明らかに品質の低いスパムリンクのみを対象にすれば、サイトの評価は健全化されます。ただし、判断が難しいグレーなリンクまで誤って否認しないよう、慎重な精査が必要です。

執筆者
畔栁 洋志
株式会社TROBZ 代表取締役
愛知県岡崎市出身。大学卒業後、タイ・バンコクに渡り日本人学校で3年間従事。帰国後はデジタルマーケティングのベンチャー企業に参画し、新規部署の立ち上げや事業開発に携わる。2024年に株式会社TROBZを創業しLocina MEOやフォーカスSEOをリリース。SEO検定1級保有



NEXT
SERVICE
サービス