ナレッジハブ
![]()
2026/2/2
データハイジーンとLLMO:AIに「信頼されるサイト」になるための情報の掃除術

AIが情報を読み取る際に障害となる「データノイズ」の正体と、それを排除するデータハイジーン(衛生管理)の基礎知識
HTMLタグの誤用や全角・半角の表記ゆれなど、人間には些細でもAIにとっては致命的なエラーを修正する具体的な手法
リンク切れや過度な広告配置など、サイトの「健康状態」を悪化させる要因を取り除き、マシンリーダブルな環境を整える手順
「渾身の記事を書いたのに、ChatGPTやPerplexityなどのAI検索で全く引用されない…」
そんな悩みを抱えているなら、記事の内容そのものではなく、データを格納している「器(うつわ)」の状態を見直す時期かもしれません。私たちが普段、部屋が散らかっていると探し物が見つからないのと同じように、ウェブサイト内部のデータが整理整頓されていないと、AIはあなたの貴重な情報を正しく見つけ出し、理解することができないのです。
これを解決するのが、「データハイジーン(情報の清潔さ)」という考え方です。これからのSEOは、人間への読みやすさはもちろんのこと、AIにとっての読みやすさ(マシンリーダブル)を追求する「LLMO(大規模言語モデル最適化)」がカギを握ります。
これから、私が数多くのサイト改善で実践してきた、AIに愛されるための「徹底的な大掃除」のノウハウを共有します。専門的な知識がなくても大丈夫です。一つずつ、一緒にサイトの汚れを落としていきましょう。
目次
1. ノイズの多いデータはAIに無視される
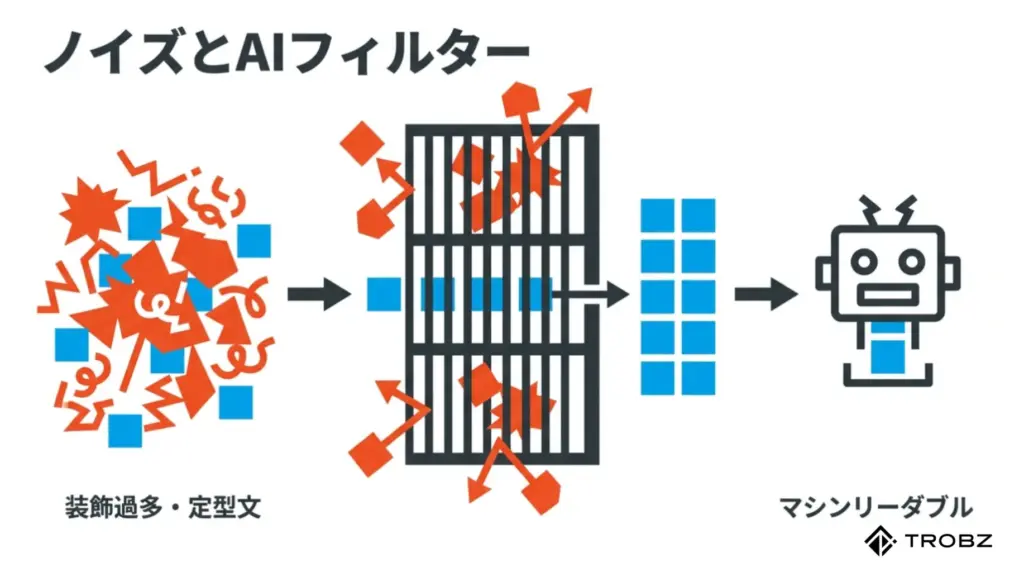
AI、特に大規模言語モデル(LLM)は、膨大なテキストデータを学習して賢くなっています。しかし、彼らは何でもかんでも食べているわけではありません。実は、学習効率を上げるために、質の低いデータや意味をなさないデータを「ノイズ」としてフィルタリング(除外)していることをご存じでしょうか。
つまり、あなたのサイトにノイズが多いと判断された瞬間、どれだけ素晴らしい独自見解が書かれていても、AIの学習対象から外され、検索結果(回答)に表示されるチャンスを失ってしまうのです。
AIが嫌う「ノイズ」の正体とは
では、具体的に何がノイズになるのでしょうか。私が現場で診断する際、真っ先にチェックするのは「本文と無関係な情報の比率」です。
人間は視覚的に「ここは広告だな」「ここはメニューだな」と瞬時に判断して本文だけを読むことができます。しかし、HTMLコードを解析するAIにとって、適切にマークアップされていないページは、情報のゴミ山のように映ることがあります。
- 過剰な装飾タグの乱用:
見た目を整えるために無意味な``タグや“タグが何層にも入れ子になっている状態は、テキストの抽出を困難にします。 - 意味のない文字列の羅列:
デザイン上の理由で画像化されていないアスキーアートや、過度な絵文字の連打、意味不明な記号の羅列などは、言語解析の精度を落とすノイズとなります。 - ボイラープレート(定型文)の肥大化:
ヘッダー、フッター、サイドバーにある「全ページ共通の定型文」が、メインコンテンツよりも文字数が多い場合、AIは「このページの固有の価値は低い」と判断しがちです。
「クリーンなデータ」と「ダーティなデータ」の境界線
データハイジーンの第一歩は、自分のサイトがAIにとって「美味しい食材(クリーンデータ)」なのか、「食べられない殻(ダーティデータ)」なのかを客観視することです。
以下の表に、AIの視点から見た「好まれるデータ」と「無視されるデータ」の特徴をまとめました。あなたのサイトの現状と照らし合わせてみてください。
特にLLMは「次に来る単語を予測する」という仕組みで動いています。文法が崩壊していたり、論理構成が破綻していたりする文章は、予測の精度を下げるため、学習データとしての優先度を下げられてしまいます。
データハイジーンとは、単にきれい好きになることではありません。「私のサイトは信頼できる情報源ですよ」というシグナルを、AIに対して送り続けるための生存戦略なのです。まずは、ご自身のサイトの記事本文だけをプレーンテキストとして抽出したときに、スムーズに読めるかどうか確認してみることから始めましょう。
2. HTMLタグの誤用と構造化エラーの修正
WebサイトにおけるHTMLタグは、AIに対する「手紙の宛名書き」のようなものです。宛名が乱雑だと郵便屋さんが困るように、HTMLタグが間違った使われ方をしていると、AI(クローラー)は情報の重要度や階層構造を正しく理解できません。
「ブラウザで見たときに崩れていなければいいのでは?」と思うかもしれませんが、それは人間用(レンダリング後)の話です。AIはレンダリング前のソースコードやDOMツリーを見て、情報の構造を解析しています。ここで発生している「意味的なエラー」こそが、LLMOにおける致命傷となり得ます。
よくある「意味を壊す」HTMLの使い方は?
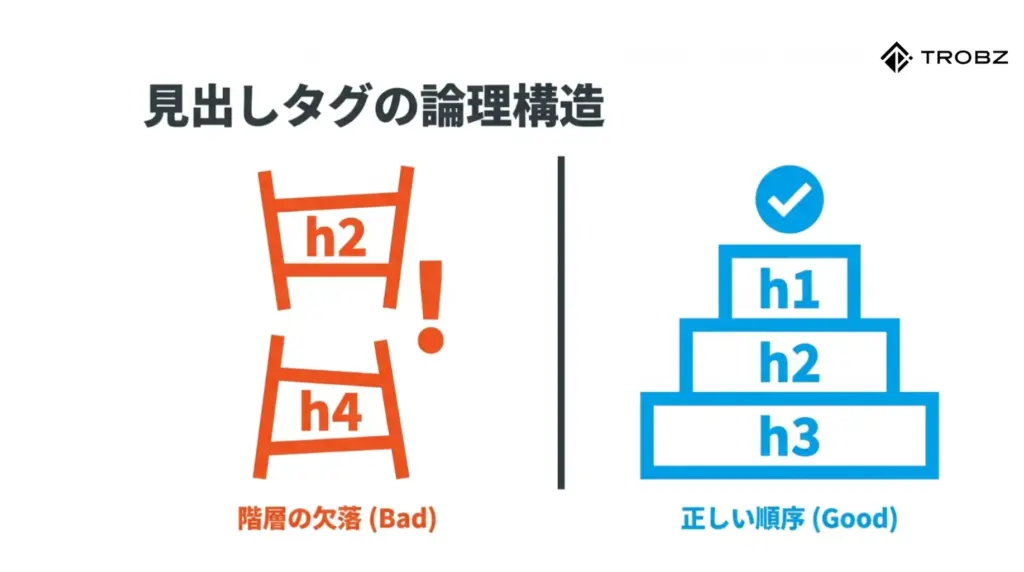
私がサイト診断を行う中で、驚くほど頻繁に見かけるのが「見出しタグ(hタグ)」の誤用です。見出しは本の目次に相当する最重要要素ですが、これを単なる「文字サイズを大きくする装飾タグ」として使っているケースが後を絶ちません。
- 階層の飛び越え:
h2タグの下に、h3を飛ばしてh4タグを使っていませんか? AIはこれを「章立てが欠落している論理的欠陥」とみなす可能性があります。h1からh6まで、数字の順序を守って階段状に構成するのが鉄則です。 - デザイン目的のhタグ使用:
サイドバーの「プロフィール」やフッターの「お問い合わせ」という文字を大きくしたいだけでh2タグを使っていませんか? これにより、記事本文のトピックと無関係な言葉が「ページの主要テーマ」として誤認されるリスクがあります。これらはCSSで文字サイズを調整すべき箇所です。
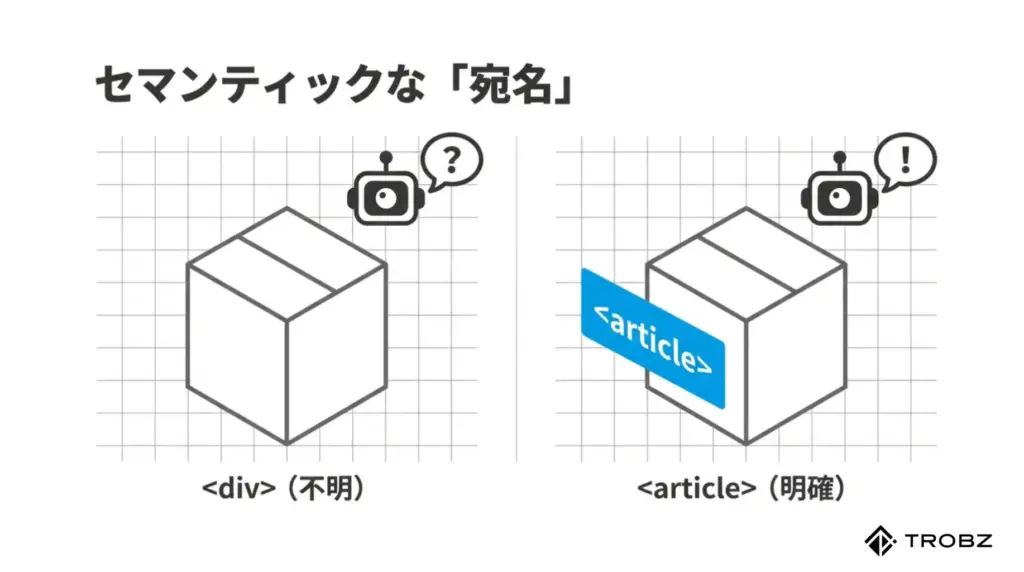
セマンティックHTMLで「意味」を伝える
AIに正確に情報を伝えるためには、`
`ばかりを使うのをやめ、HTML5から導入された「セマンティックタグ(意味を持つタグ)」を積極的に使う必要があります。
これは、「ここは記事の本文ですよ(article)」「ここはナビゲーションですよ(nav)」と、情報の役割をAIに明示する作業です。以下の表で、修正すべきポイントを確認しましょう。
特に``タグの使いすぎには注意が必要です。記事の半分が太字になっているようなページは、AIにとって「何が重要かわからない(すべてが重要=何も重要でない)」状態になります。本当に伝えたいキーワードや結論部分に絞って使用することが、ハイジーン(衛生管理)の基本です。
3. 表記ゆれの統一(全角・半角、用語)
人間であれば、「スマホ」と書いてあろうが「スマートフォン」と書いてあろうが、あるいは「SmartPhone」だろうが、瞬時に「同じもの」として認識できます。しかし、コンピューターにとってこれらは、最初はまったく別の文字列(バイト列)として処理されます。
近年の高度なAIは文脈から類義語を判断できるようになりましたが、それでも表記ゆれは学習コストを高め、情報の検索精度(エンティティの紐付け)を鈍らせる「ノイズ」であることに変わりありません。
エンティティ(実体)をAIに正しく認識させる
特に、あなたのビジネスにおける専門用語や商品名、ブランド名において表記ゆれがあるのは致命的です。AIは世界中の情報を「ナレッジグラフ(知識のネットワーク)」として整理していますが、表記がバラバラだと、一つの点(ノード)として正しく結びつかない可能性があります。
私がクライアントに推奨しているのは、以下のような「用語統一ルール(スタイルガイド)」の策定と徹底です。
- カタカナ語の長音記号:
「コンピューター」か「コンピュータ」か。JIS規格では末尾の長音を省略する傾向がありますが、Webメディアでは長音ありが一般的です。サイト全体でどちらかに統一しましょう。 - 英数字の全角・半角:
「100円」と「100円」、「AI」と「AI」。プログラミングやデータ処理の観点からは、英数字は「半角(1バイト文字)」に統一するのが絶対的な正解です。全角英数はマシンリーダブルではありません。 - 送り仮名のルール:
「申し込み」か「申込み」か、「行う」か「行なう」か。公用文のルールや記者ハンドブックなどを参考に、基準を設けます。
サイト内検索やタグ機能への影響
表記ゆれは、AIだけでなく、サイト内の検索機能やタグ機能にも悪影響を及ぼします。
例えば、ある記事には「#Webデザイン」、別の記事には「#ウェブデザイン」というタグが付けられていたとしましょう。これでは、ユーザーがタグをクリックした際に、本来見つかるはずの関連記事が半分しか表示されません。これは「回遊率の低下」を招き、結果としてサイトの滞在時間や評価を下げる要因となります。
リライトの際は、単に文章を書き直すだけでなく、「Ctrl+F(検索)」を使って、揺れがちなキーワードを一括検索し、表記を統一する作業を必ず工程に組み込んでください。この地道な「掃除」が、データの純度を高め、AIからの信頼を勝ち取る土台となります。

4. リンク切れや画像の表示エラー解消
Webサイトにおける「リンク切れ(404エラー)」は、情報のハイジーンにおいて最もわかりやすく、かつダメージの大きい「不衛生」な状態です。ユーザーにとってクリックした先にページがないことがストレスであるのと同様に、AI(クローラー)にとっても、それは「情報の断絶」を意味します。
検索エンジンのボットはリンクを辿ってWebの世界を旅しています。行き止まり(デッドリンク)が多いサイトは、「メンテナンスされていない放置された廃墟」と判断され、クロールの頻度(回遊してくれる回数)を減らされてしまいます。
「信頼性」を損なう外部リンク切れ
特に注意が必要なのは、自サイト内のリンクだけでなく、「外部サイトへの発リンク」です。過去に引用したニュース記事や参考サイトが閉鎖され、リンク切れになっているケースは非常によくあります。
AIはE-E-A-T(信頼性など)を評価する際、「どんなソースを引用しているか」も見ています。リンク先が存在しない、あるいは怪しいドメインに変わっている場合、あなたの記事の信頼性までもが連帯責任で疑われてしまうのです。
- 定期的なチェック体制:
「Broken Link Checker」などのWordPressプラグインや、オンラインのチェックツールを使い、月に一度はサイト全体の健康診断を行いましょう。 - 修正のアクション:
リンク先が消えている場合は、「リンクを削除する」か、「Wayback Machine(Webアーカイブ)のURLに差し替える」、あるいは「別の信頼できる新しい情報源に張り替える」といった処置が必要です。
画像のリンク切れは「視覚情報」の欠落
マルチモーダルAI(画像も理解できるAI)の時代において、画像が表示されない(×マークが出る)状態は、テキストの誤字以上に深刻です。SGEなどのAI検索は、回答に合わせて画像も表示しようとしますが、ソース元の画像がエラーであれば、当然その枠には採用されません。
画像が表示されない主な原因には以下のようなものがあります。
- ファイルパスの記述ミス:
相対パスと絶対パスの間違いや、ファイル名のスペルミス。 - 混合コンテンツ(Mixed Content):
サイトはSSL化(https)されているのに、画像だけ「http」で読み込もうとして、ブラウザがブロックしているケース。 - 画像の削除・移動:
メディアライブラリの整理中に誤って削除してしまった場合。
「たかが画像」と思わず、すべてのメディアが正常に表示される状態を維持することが、AIに対して「このサイトは現役で稼働しており、管理が行き届いている」とアピールする強力なシグナルになります。
5. 広告過多なページの評価低下
サイト運営において収益化は重要ですが、広告の配置方法を一歩間違えると、データハイジーンを著しく損なう要因となります。AIはユーザーの利便性を最優先するよう設計されているため、メインコンテンツの閲覧を妨げるような「ノイズだらけのページ」を徹底的に嫌います。
Googleは以前から「ページレイアウトアルゴリズム」によって、ファーストビュー(スクロールせずに見える範囲)が広告で埋め尽くされているサイトの評価を下げてきました。LLMOの観点からも、本文データの抽出を邪魔する広告コードは百害あって一利なしです。
AIが読み取りにくい「汚れたDOM」
広告配信システム(アドネットワーク)のスクリプトは、動的に大量のHTMLタグを生成します。記事の本文の途中に、脈絡なくこれらのコードが大量に挿入されると、AIが「どこまでが記事の続きなのか」を見失う原因になります。
特に、自動挿入型の広告(オート広告)を使っている場合、予期せぬ場所に広告が入り込み、文章の論理構造を分断してしまうことがあります。これは、AIによる要約や回答生成の精度を大きく低下させます。
以下に、AIとユーザーの両方に嫌われないための広告配置ガイドラインをまとめました。
CLS(視覚的な安定性)を守る
広告が遅れて読み込まれることで、本文がガクッと下にずれる現象(レイアウトシフト)も嫌われます。これはCore Web Vitalsの「CLS」という指標で評価されますが、AIも「読み心地の悪さ」としてマイナス評価します。
広告枠にはあらかじめ`min-height`などで高さを確保しておき、画像や広告が読み込まれてもレイアウトが崩れないように実装すること。これが、清潔でプロフェッショナルなサイトの証となります。
6. 重複コンテンツの整理(カニバリゼーション)
サイトを長く運営していると、知らず知らずのうちに似たようなテーマの記事が増えてしまうことがあります。「SEO対策のために記事数を増やさなければ」という焦りが、結果として「カニバリゼーション(共食い)」を引き起こし、AIからの評価を分散させているケースが後を絶ちません。
データハイジーンの観点では、重複コンテンツは「情報の散らかり」そのものです。AIは「結局、このサイトにおける『〇〇』の正解ページはどれなのか?」と迷ってしまい、結果としてどのページも検索結果(回答)の候補から外してしまうのです。
「似ている記事」がAIを混乱させるメカニズム
例えば、あなたが「ダイエット 食事」というテーマで、過去に以下の3つの記事を書いたとします。
- 2020年:ダイエットにおすすめの食事メニュー10選
- 2022年:痩せるための食事制限のコツとレシピ
- 2024年:【最新版】ダイエット中の食事はこれで決まり!完全ガイド
人間なら「最新版を見ればいい」と判断できますが、AIや検索エンジンは違います。3つの記事がそれぞれ「ダイエット」「食事」というキーワードを大量に含んでおり、内容も6〜7割重複している場合、AIはこれらを「低品質なコピーコンテンツの集合体」とみなす可能性があります。
重要なのは、1つのテーマにつき、最強の回答ページを1つだけ用意することです。これを「情報の正規化」と呼びます。
重複コンテンツを解消する3つのステップ
カニバリゼーションを解消し、AIに「このページが代表です」と伝えるためには、以下の手順で整理を行います。これはサイトの大掃除の中で最も痛みを伴いますが、最も効果が高い作業でもあります。
特に「301リダイレクト」は重要です。単に記事を削除して404エラーにしてしまうと、そのページが持っていた被リンクなどの資産が消滅してしまいます。古いページから新しいページへ、ユーザーもAIもスムーズに案内する動線を作ること。これがWeb上の「おもてなし」であり、ハイジーンの基本です。
7. 古い情報の削除またはアーカイブ化
「コンテンツは資産」という言葉を信じて、10年前に書いた日記のような記事や、終了したキャンペーンの告知ページをそのまま放置していませんか? 残念ながら、賞味期限の切れた情報は、資産ではなく「負債(ゴミ)」になります。
LLMO(AI最適化)の観点では、情報の鮮度(Freshness)は信頼性の指標の一つです。サイト全体の記事数が1000あっても、そのうち800記事が「現在は使えない情報」であれば、サイト全体の信頼スコアは大きく下がります。
低品質ページ(Low Quality Content)の断捨離
Googleの検索アルゴリズムには「低品質なページがサイト内に大量にあると、高品質なページの評価まで足を引っ張る」という性質があります。これはAIの学習においても同様です。ノイズの多いデータセットから正確な知識を抽出するのは困難だからです。
私は定期的に、以下の基準で「記事の棚卸し」を行っています。
- 過去1年間、誰にも読まれていない(PVがほぼゼロ)記事:
存在意義を問い直します。リライトして蘇らせる価値があるか、それとも削除すべきか。 - 情報が明らかに古い記事:
「2015年のSEOトレンド」など、歴史的資料としての価値しかないものは、通常の検索結果に出す必要がありません。 - 内容が薄すぎる記事:
「今日はランチに行きました。美味しかったです」だけのブログ記事などは、専門性を示すサイトであればノイズでしかありません。
「noindex」を活用したアーカイブ戦略
「削除するのは忍びない」「記録として残しておきたい」という場合は、物理的に削除するのではなく、検索エンジンに対して「インデックス登録しない(検索結果に出さない)」ように指示を出す方法があります。
これがnoindexタグの活用です。metaタグに<meta name="robots" content="noindex">と記述することで、ページ自体は存在して閲覧もできますが、AIの学習対象や検索エンジンの評価対象からは外れます。
【実践アクション:情報の仕分け】
- リライト(更新): 今でも需要があるテーマなら、最新情報に書き換えて公開日を更新する。
- 削除(404/410): 誤った情報や、重複コンテンツで価値がないものは完全に削除する。
- アーカイブ(noindex): 社内報や過去のイベントログなど、記録として残すが検索流入を狙わないもの。
部屋の掃除と同じで、不要なものを捨てると、本当に大切なものが輝き出します。サイトをスリム化することで、AI(クローラー)は重要なページだけを頻繁に巡回できるようになり、結果として新しい情報の反映スピードも向上します。
8. メタデータの正確な設定
記事本文(Body)の掃除が終わったら、次はHTMLのヘッド部分(Head)、つまり「メタデータ」の点検です。ここはユーザーの目には直接触れにくい部分ですが、AIにとっては「この記事の身分証明書」とも言える極めて重要なエリアです。
タイトルタグ、メタディスクリプション、OGP(SNS用設定)などが正しく設定されていないと、AIはページの内容を誤解したり、魅力を過小評価したりします。特にSGEにおいては、メタデータが回答の要約生成に使われるケースも確認されています。
AIに「要約」を委ねないためのディスクリプション
Googleは検索結果のスニペット(説明文)を自動生成することが多いですが、それでもmeta descriptionを設定する意味は失われていません。むしろ、AIに対して「この記事はこういう内容ですよ」と、製作者側の意図した要約(Official Summary)を提示するプロンプトとして機能します。
良いメタディスクリプションの条件は以下の通りです。
- 結論を含める:
「〇〇について解説します」ではなく、「〇〇の解決策は△△です。その理由と手順を5ステップで解説します」と具体的に書く。 - キーワードを自然に盛り込む:
検索される用語を含めることで、AIのマッチング精度を高める。 - 文字数はスマホ基準で:
PC向けに長々と書かず、70〜80文字程度で重要な情報を言い切る。
構造化データ(JSON-LD)で意味を定義する
データハイジーンの総仕上げとして欠かせないのが「構造化データ」の実装です。これは、HTMLの中に「マシン専用の解説書」を埋め込む技術です。
例えば、記事の中に「鈴木一郎」という文字があったとします。人間なら文脈で人名だと分かりますが、AIには単なる記号列です。そこで、構造化データを使って「これは『Person(人物)』であり、『Author(著者)』です」と定義してあげるのです。
構造化データに記述ミス(カンマの忘れなど)があると、AIはデータを読み取れず、逆に「エラーのあるサイト」として認識してしまいます。Googleの「リッチリザルトテスト」などのツールを使い、エラーのない清潔なJSON-LDを記述することが求められます。
9. クリーンなコードを書く重要性
ここまでは「情報の意味」に関する掃除の話でしたが、ここでは「プログラミングコードそのもの」の掃除について解説します。WebページはHTML、CSS、JavaScriptというコードで構成されていますが、これらの記述が汚い(冗長、不要な記述が多い)と、AIのクロール効率を下げ、サイトのパフォーマンス(表示速度)を悪化させます。
「表示速度」と「AI評価」は密接に関係しています。GoogleはCore Web Vitalsという指標をランキング要因にしており、表示が遅いサイトはユーザー体験が悪いと判断されるからです。
DOM要素数の削減(HTMLのダイエット)
WordPressのページビルダーや、高機能なテーマを使っていると、知らず知らずのうちにHTMLタグが「過剰包装」の状態になっていることがあります。たった一行の文章を表示するために、10重もの`
`タグで囲まれているような状態です。
DOM(Document Object Model)要素数が多すぎると、ブラウザの処理が重くなるだけでなく、AIがコンテンツの構造を解析する際の負荷も増えます。
- 不要なdivを削る: デザインのためだけにある空のdivタグなどは、CSSの`::before`や`::after`擬似要素で代用できないか検討します。
- プラグインの断捨離: 便利だからと入れたプラグインが、使っていないページでも大量のHTMLやスクリプトを出力していることがあります。機能が重複しているプラグインは削除しましょう。
JavaScriptとCSSの最適化
画面に見えない部分で読み込まれるJavaScriptファイルやCSSファイルも、データハイジーンのチェック対象です。特に「レンダリングブロック」と呼ばれる、ページの表示をせき止めてしまうスクリプトは排除すべきです。
【実践テクニック:コードの圧縮と非同期化】
- Minify(圧縮): 改行やスペースを削除してファイルサイズを小さくする。多くのキャッシュ系プラグインで設定可能です。
- Defer / Async(非同期読み込み): JavaScriptを読み込んでいる間もページの描画を止めないように、`

執筆者
畔栁 洋志
株式会社TROBZ 代表取締役
愛知県岡崎市出身。大学卒業後、タイ・バンコクに渡り日本人学校で3年間従事。帰国後はデジタルマーケティングのベンチャー企業に参画し、新規部署の立ち上げや事業開発に携わる。2024年に株式会社TROBZを創業しLocina MEOやフォーカスSEOをリリース。SEO検定1級保有



NEXT
SERVICE
サービス