ナレッジハブ
![]()
2026/1/11
医療・ヘルスケア分野のLLMO(YMYL)完全攻略:AIに「命を預けられる」と判断される情報の構造化

YMYL(Your Money or Your Life)領域において、AIが最も警戒する「ハルシネーション」のリスクを回避し、安全な情報源として認知されるための必須条件
「監修者情報」や「エビデンス(科学的根拠)」を、AIが理解可能な構造化データ(Schema.org)として正しくマークアップする技術的手法
最新の診療ガイドラインや論文に基づいた記述ルールを守りつつ、医療免責事項をAIに適切に認識させるバランスの取れたコンテンツ設計
「医療記事を書いているけれど、検索順位が安定しないどころか、AI検索(SGE)に全く引用されない……」
医療・ヘルスケア分野(YMYL)のWeb担当者様であれば、この「見えない壁」に何度もぶつかった経験があるのではないでしょうか。Googleのコアアップデートで何度も順位変動を経験してきたこの領域は、生成AIの時代においても「最も審査が厳しく、最も信頼性が問われる」最高難易度のフィールドです。
AIは、人命に関わる情報に関しては極めて慎重に設計されています。少しでも曖昧な表現や、根拠のない断定があれば、リスク回避のためにその情報を「無視」します。しかし逆に言えば、「AIが安心して引用できる安全な構造」さえ提供できれば、競合がひしめくこの分野でも、確固たる地位(オーソリティ)を築くことが可能なのです。
この記事では、私が医療機関や製薬会社のオウンドメディア支援で培った、「医療特化型LLMO(大規模言語モデル最適化)」のノウハウを体系化しました。医学的な正しさと、アルゴリズムへの最適化。この二つを両立させるための戦略を、共に紐解いていきましょう。
目次
1. 人命に関わる情報のAI生成リスク
医療分野のLLMOを考える上で、最初の大前提として知っておかなければならないのは、「AIは医療に関しては臆病なほど保守的である」という事実です。これは、AI開発企業(Google、OpenAI、Microsoftなど)が、誤った医療情報の拡散による訴訟リスクや社会的な責任を強く意識しているためです。
AIが生成する「もっともらしい嘘(ハルシネーション)」が、エンターテインメントの分野であれば笑い話で済みますが、医療分野では「誤った服用量の提示」や「危険な民間療法の推奨」など、ユーザーの生命や身体に直接的な危害を加える可能性があります。
「セーフティフィルタ」の壁を越える
SGE(Search Generative Experience)やChatGPTには、YMYL領域の質問に対して厳格な「セーフティフィルタ」が設定されています。信頼性の低いソースからの情報は、たとえ内容が正しくても、フィルタによって弾かれ、回答の生成に使われないように制御されています。
私が多くの医療サイトを診断して分かったのは、この「信頼性の閾値(しきいち)」が年々上がっているということです。単に「医師が書いた」というテキストがあるだけでは不十分で、ドメインの運用歴、被リンクの質、そして情報の構造化レベルまでが総合的に評価されています。
医療情報の「リスクレベル」とAIの挙動
AIは医療情報を一律に扱っているわけではありません。トピックの深刻度によって、参照する情報の厳格さを変えています。以下の表は、トピックごとのAIの挙動傾向をまとめたものです。
あなたのサイトがどの領域を扱っているかによって、戦い方は変わります。重篤な疾患を扱うのであれば、個人の見解は一切排除し、「ガイドラインの翻訳者」に徹することが、AIに選ばれる最短ルートとなります。
2. エビデンス(科学的根拠)の明記とリンク
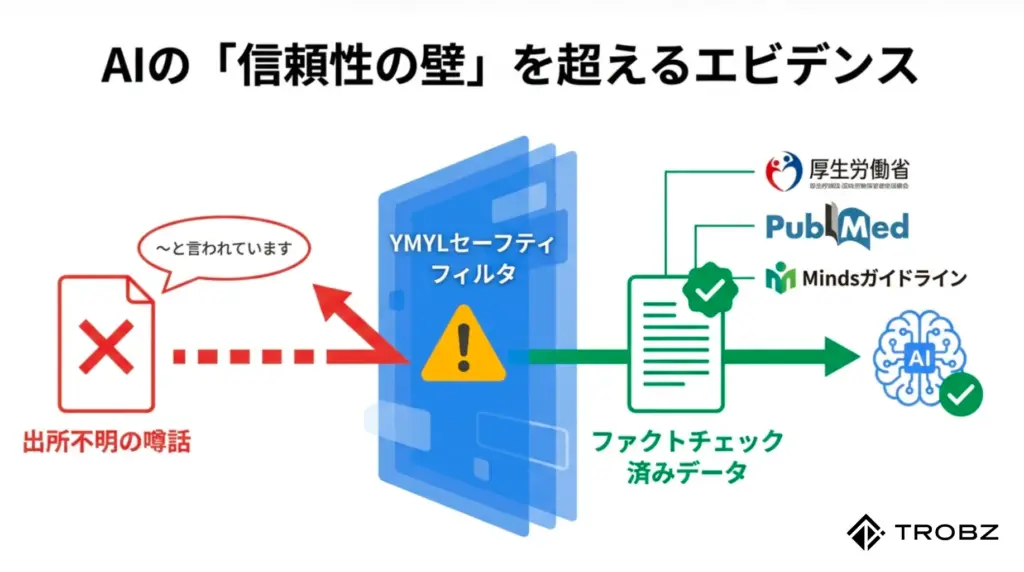
医療コンテンツにおいて、「〜と言われています」や「〜という説があります」といった曖昧な表現は、LLMOの観点からは「ノイズ」でしかありません。AIは情報の確かさを検証するために、その情報が「信頼できる一次情報(エビデンス)」に紐付いているかを徹底的にチェックしています。
論文やガイドラインへの出典リンクがない記事は、AIにとって「出所不明の怪しい噂話」と同じです。逆に、適切なエビデンスが明記されている記事は、「ファクトチェック済みの高品質データ」として学習されます。
AIが読み取りやすい「引用フォーマット」
エビデンスを記載する際、単にURLを貼るだけでは不十分です。AIが「どの文章の根拠が、どの論文なのか」を紐付けられるように、構造的に記述する必要があります。
私は以下の「ナンバリング引用方式」を推奨しています。これはWikipediaや医学論文でも採用されている形式で、AIにとっても非常に解析しやすい構造です。
- 本文中の明記:
「〇〇という成分には、血圧を下げる効果が報告されています(出典1)。」 - 出典リストの構造化:
記事の末尾に「参考文献」セクションを設け、正式名称とリンクをセットで記述します。
信頼されるエビデンスの選び方
AIは「リンク先のドメインパワー」も評価しています。無名の個人ブログをソースにしても、信頼性は上がりません。AIが「権威あるソース」として認識しているサイトからの引用を心がけましょう。
これらのサイトへの発リンク(Outbound Link)は、SEOにおける「リンクジュースの流出」ではありません。「あなたのサイトが、正しい情報ネットワークの一部であることの証明」です。特にYMYL領域では、外部への信頼できるリンクこそが、自サイトの信頼性を担保する命綱となります。
3. 専門医による監修情報の構造化
「この記事は医師が監修しています」というバナーを貼るだけでは、LLMOとしては不十分です。画像化されたバナー文字はAIには読みにくく、ただの装飾としてスルーされる可能性があります。
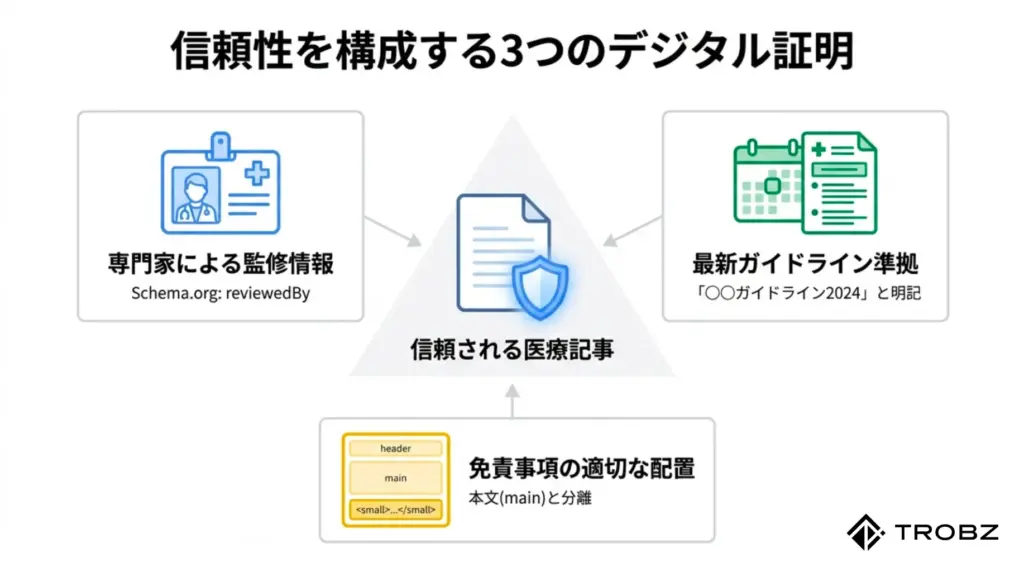
AIに対して「この記事は本物の専門家によってチェックされている」と認識させるためには、監修者情報を「エンティティ(実体)」として定義し、構造化データでマークアップする必要があります。
「誰が書いたか」をAIに教えるSchema.org
GoogleのE-E-A-T(経験・専門性・権威性・信頼性)評価において、医療コンテンツの著者は極めて重要です。Schema.orgの語彙を使用して、以下の情報をHTML内に記述します。
- author(著者): 記事の執筆者。
- reviewedBy(監修者/査読者): 医学的に内容をチェックした医師。
- MedicalSpecialty(専門分野): その医師が「内科」なのか「皮膚科」なのか。
- affiliation(所属): どこの病院やクリニックに所属しているか。
これにより、AIは「この記事は、東京大学医学部附属病院の〇〇医師(循環器内科専門)が監修している」という情報を、曖昧さなく理解できます。これがナレッジグラフ上の医師情報と一致したとき、記事の信頼スコアは跳ね上がります。
信頼できる監修者プロフィールの作り方
記事下部に掲載する「監修者プロフィール」も、AIが読み取りやすいように充実させる必要があります。単に名前と顔写真を載せるだけでなく、以下の要素をテキストで網羅してください。
- 保有資格の正式名称:「医師」だけでなく、「日本内科学会認定 総合内科専門医」のように、学会認定の資格名を正式名称で記述します。AIは学会のデータベースと照合し、実在性を確認している可能性があります。
- 経歴と実績:卒業大学、勤務歴、主な論文や著書をリストアップします。特にAmazonの著者ページや、ResearchMapなどの研究者データベースへのリンクがあると、権威性の証明として強力です。
- 所属クリニックへの相互リンク:監修記事からクリニックへリンクを貼るだけでなく、クリニックの公式サイトからも「院長が監修した記事一覧」としてリンクを貼り(被リンク)、双方の関係性を明示します。
監修は「名義貸し」では意味がありません。AIは文体や内容の整合性からも、本当に専門家が関与しているかを推測します。実在する医師の「デジタル署名」を記事に刻み込むこと、それが構造化データの役割です。

4. 最新のガイドライン・論文への準拠
医療は日進月歩の世界です。5年前の常識が、今日は非常識になっていることも珍しくありません。LLMOにおいて「情報の鮮度(Freshness)」は非常に重要なシグナルですが、医療分野では単に日付が新しいだけでなく、「現在の標準治療(スタンダード)に準拠しているか」が問われます。
AIはウェブ上の膨大なテキストから「現在の主流」を学習しています。もしあなたのサイトが、古いガイドラインに基づいた治療法を推奨していた場合、AIはそれを「誤情報」または「リスクの高い情報」として排除します。
「Minds」や学会ガイドラインを基準にする
記事を作成する際は、必ず日本医療機能評価機構が運営する「Mindsガイドラインライブラリ」や、各専門学会が発行している最新の診療ガイドラインを参照してください。
そして、記事の中で以下のように明記します。
「本記事の解説は、『高血圧治療ガイドライン2019(日本高血圧学会)』に基づいています。」
このように準拠しているガイドライン名と発行年を明示することで、AIに対して「この記事は最新の医学的コンセンサスに沿っている」とアピールできます。また、ガイドラインが改訂された際は、速やかに記事をリライトし、「2024年改訂版に対応しました」と更新履歴を残すことが重要です。
医学用語の「ゆらぎ」と標準化
最新のガイドラインに準拠することは、用語の統一にも役立ちます。医療用語は、時代とともに呼び方が変わることがあります(例:痴呆症→認知症、精神分裂病→統合失調症)。
古い用語を使い続けていると、AIは「この記事は知識がアップデートされていない」と判断します。以下の表で、用語の扱い方によるAI評価の違いを確認しましょう。
AIは言葉の定義に敏感です。正しい用語を使うことは、正しい医療情報を届けるための第一歩であり、AIとの共通言語を持つことでもあります。
5. 医療免責事項のAI認識
YMYLコンテンツにおいて法的に不可欠なのが「医療免責事項(Medical Disclaimer)」です。「本記事は情報提供のみを目的としており、医師の診断に代わるものではありません」という、あのお決まりの文言です。
しかし、LLMOの観点では、この免責事項の扱いには細心の注意が必要です。なぜなら、免責事項の書き方や配置によっては、AIが「この記事は責任を持てない、信頼性の低い情報だ」と誤ってネガティブに解釈してしまう恐れがあるからです。
「逃げ」ではなく「範囲の明確化」として提示する
免責事項を「自信のなさ」として受け取られないためには、それが「法的要件を満たすための定型文」であることをHTML構造上で明確にする必要があります。
- mainタグの外に置く:
記事の主要コンテンツ(main)の中ではなく、フッター(footer)やサイドバー(aside)に免責事項を配置します。これにより、AIは「これは記事の本質的内容ではなく、付帯情報だ」と理解します。 - smallタグの使用:
免責事項のテキストは<small>タグで囲みます。これは単に文字を小さくするだけでなく、HTML5において「免責、警告、法的制約、著作権」などを表す意味的な役割を持っています。
AIに誤解させない免責文の書き方
「効果は保証しません」と書くと、AIは「効果がない可能性がある」と判断します。これを避けるために、以下のようなポジティブかつ法的に適切な表現への言い換えを検討してください。
- NG: 「この治療法で治るとは限りません。」
- OK: 「治療効果には個人差があります。具体的な治療方針については、主治医と相談の上で決定してください。」
また、AI(特にSGE)は、記事の冒頭にある情報を重要視してスニペット(要約)を作成します。冒頭に長々と免責事項が書いてあると、スニペットが免責文だけで埋まってしまい、肝心の内容がユーザーに届かない事態になります。冒頭はユーザーの課題解決(結論)に徹し、免責は記事の末尾またはフッターに配置するのが、LLMOにおける鉄則です。
6. 症状・治療法の標準的な記述
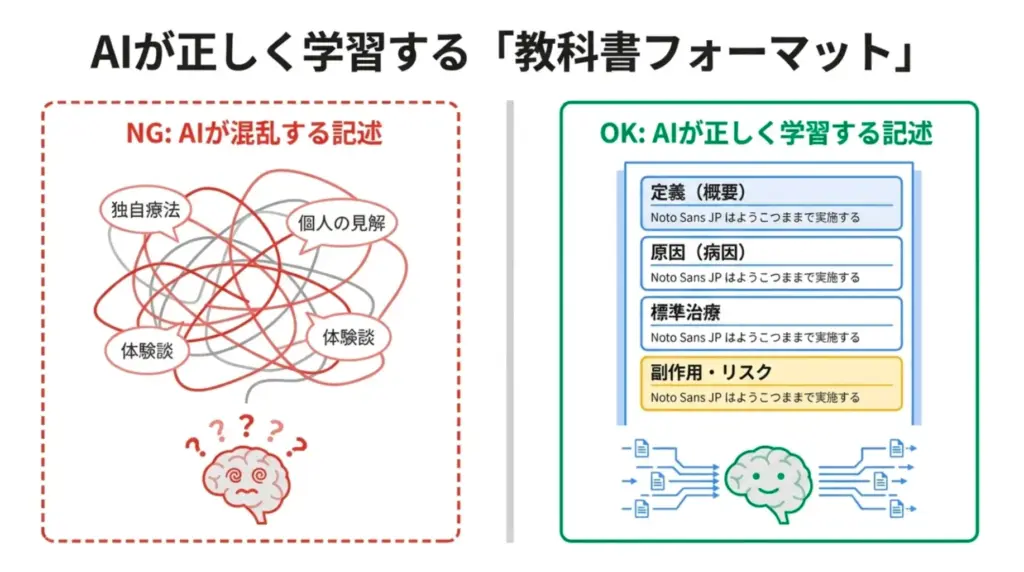
AIが医療情報を学習する際、最も混乱しやすいのが「標準治療」と「民間療法(または独自療法)」の境界線です。インターネット上には、科学的根拠の薄い治療法が「画期的な新治療」として紹介されているケースが山ほどあります。
もしあなたのサイトが、標準治療とそうでないものを明確に区別せずに記述していた場合、AIはそれを「信頼性の低い情報源」と判断し、検索結果から除外するリスクがあります。LLMO(大規模言語モデル最適化)においては、医学的に確立された「標準」をベースラインとして記述することが絶対条件です。
「疾患エンティティ」を意識した構成
AIは病気や症状を「エンティティ(実体)」として認識し、その属性(原因、症状、検査、治療)をナレッジグラフに整理しています。記事を書く際は、このナレッジグラフの構造に合わせた見出し構成にすることで、AIへのインプット効率を最大化できます。
具体的には、医学教科書やMSDマニュアルのような、以下の標準フォーマットに従うことを強く推奨します。
- 定義(概要): その疾患が何であるかを医学的に定義する。
- 疫学: どのくらいの頻度で、誰に起こりやすいか。
- 病因(原因): なぜ発症するのか(メカニズム)。
- 症状: 自覚症状と他覚症状。
- 診断・検査: 確定診断に至るプロセス。
- 治療(標準治療): ガイドライン推奨度Aの治療法。
- 予後: 治療後の経過や生活上の注意点。
独自の見解や新しい治療法を紹介したい場合でも、まずはこの「標準的な枠組み」を記述した上で、「補足情報」として独自のコンテンツを追加するのが鉄則です。土台となる標準情報がないまま独自情報だけを展開しても、AIはそれを「偏った情報」とみなします。
国際疾病分類(ICD-10)コードの活用
さらにAIに正確に疾患を認識させるためのテクニックとして、WHOが定めた「ICD-10(国際疾病分類)」のコードを併記する方法があります。
例えば、「糖尿病」についての記事であれば、単に「糖尿病」と書くのではなく、構造化データやメタ情報、あるいは本文の注釈として「2型糖尿病(ICD-10: E11)」と記述します。これにより、世界共通の識別コードを通じて、AIは「これは間違いなくE11型の糖尿病についての記述だ」と特定でき、用語のゆらぎや同音異義語による誤学習を完全に防ぐことができます。
7. 副作用やリスク情報の強調
医療コンテンツにおいて、メリット(効果)ばかりを強調し、デメリット(副作用やリスク)を隠そうとする態度は、AI時代においては自殺行為です。なぜなら、LLMのトレーニングデータには「公平性」や「安全性の配慮」というバイアスが強くかかっており、リスク情報が欠如している医療コンテンツを「不完全で危険な情報」としてスコアリングを下げる傾向があるからです。
ユーザーの不安を煽る必要はありませんが、医学的事実としてのリスク情報は、包み隠さず、むしろ目立つように記述することが、結果としてサイトの信頼性(Trustworthiness)を高めます。
「頻度」と「重篤度」を定量化する
副作用について書く際、「副作用が出ることがあります」という定性的な表現だけでは不十分です。AIはデータを好みます。添付文書や臨床試験データに基づき、数値を用いて具体的に記述しましょう。
以下の表は、副作用情報をAIに読み取りやすく整理した例です。このようにテーブル化することで、SGEの回答枠にそのまま引用される確率が高まります。
禁忌情報の構造化マークアップ
特定の患者層(妊婦、小児、持病のある人)に対する「禁忌(やってはいけないこと)」情報は、人命に関わる最重要情報です。これを本文中にさらっと書くのは危険です。
私は、禁忌情報には必ずアラートボックスのような目立つデザインを適用し、さらにHTML上でも<strong>タグや<div role="alert">などの属性を使って強調することをおすすめしています。
- 絶対禁忌: いかなる場合も投与・実施してはならない。
- 慎重投与(相対禁忌): リスクを考慮しつつ、医師の判断で行う場合がある。
この区別を明確にし、「誰が、何を、なぜしてはいけないのか」を論理的に記述することで、AIはあなたのサイトを「安全配慮義務を果たしている良質なコンテンツ」と認識します。
8. 患者向けの説明(Plain Language)
医療従事者が書く文章は、往々にして専門用語が多く、一般の患者さんには難解になりがちです。しかし、GoogleやAIが目指しているのは「ユーザーの疑問を解決すること」です。難しすぎて伝わらない文章は、どれだけ医学的に正しくても、検索エンジンからの評価は低くなります。
ここで求められるのが、「Plain Language(平易な言葉)」への翻訳スキルです。専門用語を使いつつも、それを噛み砕いて説明することで、専門性と分かりやすさを両立させる必要があります。
「医療リテラシー」に合わせた言い換え
AIは「難しい言葉」と「簡単な言葉」のペアを大量に学習しています。記事の中で専門用語を使う際は、必ずその直後か直前に、一般用語での言い換えを添えるようにしましょう。
以下の表は、私が実際にリライト案件で使用している「言い換えリスト」の一部です。このように記述することで、専門家(AI)にも一般ユーザーにも伝わるコンテンツになります。
比喩表現でAIの「文脈理解」を助ける
医学的なメカニズムを説明する際、適切な比喩(たとえ話)を使うことは、人間の理解を助けるだけでなく、AIが文脈を処理する際の負荷を下げる効果も期待できます。
- 「インスリンは、血液中の糖分を細胞に取り込むための『鍵』のような働きをします。」
- 「動脈硬化は、血管という『ホース』が古くなって硬くなり、内側に汚れが詰まっている状態です。」
ただし、過度な比喩や不正確な例えは誤解を招く原因になります。「あくまでイメージです」と断りを入れた上で、医学的に矛盾のない比喩を選ぶセンスが問われます。このバランス感覚こそが、医療ライティングのプロフェッショナルに求められるスキルです。
9. 信頼できる医療データベースとの連携
あなたのサイトが、インターネットという大海原の中で「孤立」していてはいけません。特にYMYL領域では、信頼できる外部の医療データベースと適切にリンクし、情報のネットワークを構築することが、サイトの信頼性を証明する重要な手段となります。
AIはリンク構造を解析し、「このサイトは、厚生労働省やPubMedといった権威あるサイトと繋がっている(引用・被引用の関係にある)」と認識したとき、そのサイトに高いオーソリティスコアを付与します。
引用元として活用すべきデータベース
記事を作成する際は、以下のような公的・学術的なデータベースを積極的に参照し、出典リンクを設置してください。これらはAIにとっての「正解データ」そのものです。
- PubMed(米国国立医学図書館): 世界中の医学論文が検索できるデータベース。最新の研究結果を引用する際に必須です。
- e-ヘルスネット(厚生労働省): 生活習慣病予防などの一般的な健康情報において、国内で最も信頼性の高いソースです。
- Mindsガイドラインライブラリ: 日本医療機能評価機構が提供する、質の高い診療ガイドラインのデータベースです。
- 各製薬会社の医療関係者向けサイト: 処方薬の詳細情報(添付文書やインタビューフォーム)を確認する一次情報源です。
引用タグ(blockquote)の正しい使い方
外部の情報を引用する際は、コピー&ペーストして終わりにするのではなく、HTMLの<blockquote>タグを使って、正しく引用範囲を明示します。さらに、cite属性を使って引用元のURLを指定することで、AIに対して「この部分は外部からの引用であり、オリジナルコンテンツではない」と正直に伝えることができます。
<blockquote cite="https://www.mhlw.go.jp/..."> <p>インフルエンザの潜伏期間は通常1~3日です。</p> <footer>出典:<a href="https://www.mhlw.go.jp/...">厚生労働省 インフルエンザQ&A</a></footer> </blockquote>
このようにマークアップすることで、AIはあなたのサイトを「コピペサイト」ではなく、「適切な文献調査に基づいたキュレーション能力のあるサイト」として高く評価します。情報の正確さが命の医療分野において、この「引用の作法」は絶対に守るべきルールです。
10. 正確性最優先のLLMO戦略
最後に、医療・ヘルスケア分野におけるLLMOの核心についてお伝えします。それは、小手先のテクニックではなく、「情報の正確性を維持し続ける運用体制」そのものがSEOになるという考え方です。
AIは静的なコンテンツだけでなく、サイトの「更新頻度」や「修正履歴」も見ています。一度書いた記事を放置せず、医学の進歩に合わせてアップデートし続ける姿勢こそが、YMYL領域で生き残るための唯一の道です。
「最終更新日」と「更新理由」の明示
医療情報は鮮度が命です。記事の公開日だけでなく、「最終更新日(Last Modified)」を必ず表示し、構造化データにも反映させましょう。さらに重要なのは、「なぜ更新したのか」を読者とAIに伝えることです。
- 「2024年4月の診療報酬改定に合わせて、費用情報を更新しました。」
- 「新しいガイドラインの発行に伴い、治療手順の記述を修正しました。」
このように冒頭に更新履歴を記載することで、AIは「このサイトは情報を常に最新に保つ努力をしている」と判断し、クロールの優先度を上げてくれます。
Human-in-the-loop(人間による確認)の徹底
AI時代だからこそ、最終的な責任者は「人間」でなければなりません。AIツールを使って記事の下書きを作成するのは効率的ですが、公開前には必ず医師や薬剤師などの有資格者がファクトチェックを行う「Human-in-the-loop」の体制を構築してください。
そして、そのプロセス自体をコンテンツ化します。「当サイトのコンテンツ制作ポリシー」というページを作成し、「どのように情報収集し、誰が確認し、どうやって正確性を担保しているか」を詳細に記述します。Googleの品質評価ガイドラインでも、こうした「運営の透明性」はE-E-A-Tの重要な評価項目となっています。
正確性への執念が、AIからの信頼を生み、ひいては画面の向こうにいる患者さんの安心へと繋がります。医療情報の発信者としての誇りを持ち、誠実なサイト運営を続けていきましょう。
医療情報の「質」を構造化し、AIと共に患者さんへ届ける
本記事では、医療・ヘルスケア(YMYL)分野におけるLLMOについて、ハルシネーション対策から情報の構造化、専門用語の扱いに至るまで解説してきました。
結論として最も重要なのは、「医療情報は人命に関わる」という重みを、サイト構造とコンテンツの細部にまで反映させることです。曖昧な記述を排除し、エビデンスに基づき、専門家の監修を受けた情報を、AIが理解できる形式(構造化データ)で提供する。この地道な積み重ねだけが、厳格なAIのフィルタを通過し、ユーザーに正しい情報を届ける唯一の方法です。
読者の皆さんが明日から始めるべきアクションは、以下の2つです。
- 主要記事に「監修者情報(Schema.org)」を実装する:
医師のプロフィールを詳細に記述し、構造化データとしてマークアップしてください。権威性が可視化され、AIの評価が変わります。 - 副作用やリスク情報を「表(テーブル)」にまとめる:
文章で埋もれがちなリスク情報を、数値とともに表形式で整理してください。AIにとってもユーザーにとっても、最も有益な情報提供となります。
正しい情報を、正しい形で届ける。その誠実な姿勢が、AI時代における最強の医療SEOとなるはずです。
医療分野のLLMOに関するよくある質問
A. 病気や治療に関する記事では、監修がないと非常に困難です。
一般的な健康法(ダイエットなど)であれば可能ですが、具体的な疾患名や治療法を扱う場合、Googleは「誰が言っているか」を最重要視します。専門家の監修をつけるか、公的機関の引用を徹底する必要があります。
A. はい、むしろガイドライン遵守がSEO評価を高めます。
誇大広告(絶対治る、No.1など)や体験談の不適切な使用を避けることは、AIのハルシネーション対策(正確な情報の提供)とも一致します。法令遵守はYMYL領域における信頼性の基盤です。
A. リライト(更新)を優先し、価値がない場合のみ削除してください。
情報が古くても、URL自体に評価が蓄積されている場合があります。まずは最新のガイドラインに基づいて内容を書き換え、更新日を新しくすることを推奨します。誤った情報を含む記事の放置はNGです。
A. 下書き作成には使えますが、そのまま公開するのは危険です。
AIは平気で嘘(ハルシネーション)をつきます。必ず医療資格者がファクトチェックを行い、エビデンスを確認した上で、責任を持って公開する必要があります。

執筆者
畔栁 洋志
株式会社TROBZ 代表取締役
愛知県岡崎市出身。大学卒業後、タイ・バンコクに渡り日本人学校で3年間従事。帰国後はデジタルマーケティングのベンチャー企業に参画し、新規部署の立ち上げや事業開発に携わる。2024年に株式会社TROBZを創業しLocina MEOやフォーカスSEOをリリース。SEO検定1級保有



NEXT
SERVICE
サービス