ナレッジハブ
![]()
2026/1/10
SGEとハルシネーション対策:AIに「嘘」をつかせないための正しい情報発信戦略

自社ブランドや商品に関してAIが生成する「もっともらしい嘘(ハルシネーション)」のリスクと、その発生メカニズム
公式サイトの情報を構造化し、古い情報を整理することで、AIに対して「唯一の正解」を学習させる具体的な手順
誤解を招く曖昧な表現を避け、否定表現やシンプルな文構造を用いることで、AIの認識エラーを未然に防ぐライティング技術
「自社のサービスについてChatGPTに聞いてみたら、全く存在しない『無料プラン』をおすすめされた……」
先日、あるクライアントから青ざめた顔でこんな相談を受けました。調べてみると、確かにAIはその企業のサービスについて、事実無根の機能や料金プランを自信満々に回答していました。これがいわゆる「ハルシネーション(幻覚)」と呼ばれる現象です。
GoogleのSGE(Search Generative Experience)が本格導入され、検索結果のトップにAI生成の回答が表示されるようになった今、この問題は「笑い話」では済まされません。もしAIがあなたの会社について誤った情報を数百万人のユーザーに拡散してしまったら? その損害は計り知れません。
これから、私がWebライターとして現場で実践している「AIに正しい情報を守らせるための防衛策」について、技術的な側面と言葉の選び方の両面から詳しく解説していきます。AIは決して悪意を持って嘘をつくわけではありません。正しい「教え方」さえ知っていれば、あなたのブランドを守る最強の味方になってくれるはずです。
目次
1. 自社に関する誤情報が生成されるリスク
AI検索の普及は便利である反面、企業にとっては「情報のコントロール」が難しくなるという新たなリスクをもたらしました。これまでであれば、検索結果に誤った情報のサイトが表示されても、ユーザーがクリックしなければ被害は限定的でした。しかし、SGEでは検索結果画面(SERPs)の最上部に、AIが生成した回答が直接表示されます。
ここで重要なのは、AIが生成する回答が「100%の事実に基づいているとは限らない」という点です。まずは敵を知ることから始めましょう。なぜAIは嘘をつくのか、そしてそれがビジネスにどのような打撃を与えるのかを深掘りします。
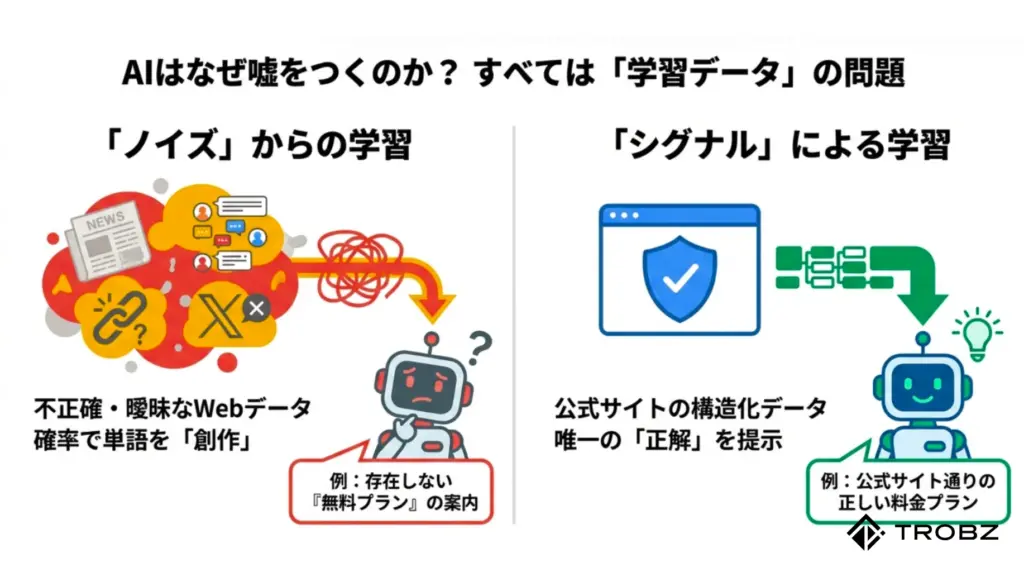
「ハルシネーション」はなぜ起こるのか?
「ハルシネーション(Hallucination)」とは、AIが事実とは異なる情報を、さも真実であるかのように生成してしまう現象のことです。まるで幻覚を見ているかのように嘘をつくことから、この名前がつきました。
なぜ高度な知能を持つAIが、単純な事実誤認をするのでしょうか。その原因は、大規模言語モデル(LLM)の仕組みそのものにあります。LLMは「辞書を引いて答えを探している」のではありません。「ある単語の次にくる確率が最も高い単語」を予測して文章を繋げているに過ぎないのです。
例えば、「〇〇社の料金は」という文の続きを予測する際、ネット上にその会社の正確な料金情報が少なかったり、競合他社の料金情報と文脈が混ざっていたりすると、AIは「月額980円です(※実際は存在しない)」といった、確率的にありそうな答えを「創作」してしまうのです。これがハルシネーションの正体です。
嘘がビジネスに与える致命的なダメージ
たかがAIの回答、と侮ってはいけません。ユーザーは「検索エンジンのトップに出ている情報だから正しいだろう」というバイアスを持っています。AIによる誤情報の拡散は、以下のような深刻なビジネスリスクに直結します。
AIは悪気があって嘘をつくわけではない
ここで理解しておきたいのは、AIには悪意がないということです。AIはあくまで学習したデータに基づいて、最も「それらしい」回答を生成しているだけです。つまり、AIが嘘をつくのは、学習元となっているWeb上のデータが不正確、あるいは曖昧であることの裏返しでもあるのです。
「AIが間違っている」と嘆く前に、「私たちの発信している情報は、AIにとって読み取りやすく、誤解の余地がないほど明確だろうか?」と自問する必要があります。SGE対策の本質は、AIを正すことではなく、AIが正しく学習できる環境を私たちが整えてあげることにあるのです。
2. 公式サイトでの正しい情報の構造化
AIのハルシネーションを防ぐための最も確実な方法は、情報の「一次情報源」である公式サイト自身が、AIに対して「これが正解ですよ」と強力なシグナルを送ることです。
人間向けの見た目を整えるだけでは不十分です。AIはHTMLコードを読み解き、情報の意味を理解しようと努めています。そこで必要になるのが、情報を「構造化」してAIに手渡すというアプローチです。
AIにとっての「正解データ」を用意する
AIはネット上のあらゆる情報を拾い食いしますが、その中でも特に「信頼できるソース」として優先するのが、公式サイトの構造化データや、Googleビジネスプロフィールなどの公式情報です。
例えば、あなたのサイトに「料金:980円」と書いてあっても、それがただのテキストなのか、画像の中の文字なのか判然としない場合、AIはそれを無視したり、別の数字と取り違えたりする可能性があります。しかし、これを「構造化データ」としてマークアップすれば、AIは「これは『Price(価格)』という属性のデータであり、値は『980』である」と100%の確信を持って理解できます。
構造化データ(Schema.org)はAIへの招待状
具体的には、「Schema.org」という規格に基づいたJSON-LD形式の記述をHTML内に追加します。これはプログラミングの知識が多少必要になりますが、WordPressなどのCMSであればプラグインで簡単に実装可能です。
自社に関する情報を守るために、特に実装すべき構造化データの種類をまとめました。
ナレッジグラフとの連携を意識する
構造化データを正しく実装し続けると、Googleはその情報を「ナレッジグラフ」という巨大なデータベースに登録します。これはGoogleが持っている「知識のネットワーク」です。
一度ナレッジグラフに「正しい情報」として登録されれば、AIはその情報を「事実(Fact)」として優先的に扱います。つまり、誰かが適当なブログで「あの会社の料金は高い」と書いていても、ナレッジグラフ上の「公式価格」の方が信頼度が高いと判断されるようになるのです。
構造化データの実装は、「AIに嘘をつかせないためのワクチン」を打つようなものです。地味な作業ですが、その効果は長期的にあなたのブランドを守り続けます。
3. 古い情報の削除と修正
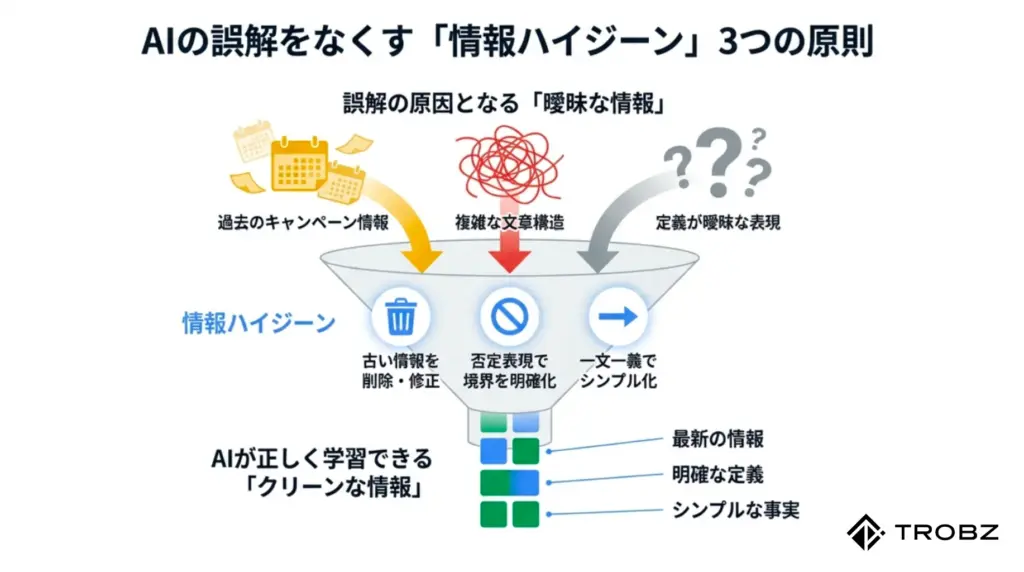
AIがハルシネーションを起こす大きな原因の一つに、「情報の鮮度(Freshness)」の問題があります。AIは最新の情報だけでなく、過去数年分のWebデータも学習しています。そのため、もしあなたのサイト内に「5年前の古い料金表」が残っていたらどうなるでしょうか?
AIは「現在の料金」と「5年前の料金」の区別がつかず、文脈によっては古い方の情報を「現在の事実」として回答してしまうリスクがあるのです。
過去の遺産が「ノイズ」に変わるとき
「いつか役に立つかもしれないから」と、古いプレスリリースやキャンペーンページをそのまま放置している企業は多いです。しかし、SGE時代において、これらは資産ではなく「AIを混乱させるノイズ」になりかねません。
例えば、「2020年限定!無料トライアル実施中」というページが残っていると、AIは「このサービスには無料トライアルがある」と学習してしまいます。ユーザーが「無料トライアル」について質問したとき、AIは悪気なくその終了したキャンペーン情報を提示し、ユーザーをぬか喜びさせてしまうのです。
サイト内の矛盾を解消するデータハイジーン
これを防ぐためには、定期的にサイト内の情報を掃除する「データハイジーン(情報の衛生管理)」が必要です。サイト内に矛盾する情報(新旧の価格、新旧の住所など)が存在しない状態を作ることが重要です。
私が推奨している情報更新のアクションプランは以下の通りです。
外部サイトに残る古い情報への対処法
自社サイトは管理できますが、厄介なのは外部のポータルサイトや個人ブログに残っている古い情報です。これらもAIの学習ソースになります。
すべての外部サイトを修正させるのは不可能ですが、影響力の大きいメディアや比較サイトに対しては、情報の修正依頼を出す価値があります。また、自社サイト内で「※他社サイト等で古い価格が表示されている場合がありますが、公式サイトの価格が正となります」といった「注意喚起」を行うこと自体を、AIに学習させるという手もあります。

4. 否定表現(〇〇ではない)を用いた明確化
AIに正確な情報を伝えるためには、「何であるか(肯定)」を伝えるだけでは不十分な場合があります。時には「何ではないか(否定)」を明確に定義することで、AIの誤解を強力にブロックすることができます。
人間の会話でも、「私はエンジニアです」と言うより、「私はデザイナーではなく、エンジニアです」と言った方が、職種の境界線がはっきり伝わることがありますよね。AIに対しても、この「境界線」を引く作業が非常に有効です。
曖昧さを排除する「境界線」の引き方
AIは関連性の高い言葉を確率的に結びつけようとします。例えば、あなたのサービスが「月額制の学習サービス」だとします。AIはこれに関連して「無料体験」「解約金」「マンツーマン指導」といった単語を連想しがちです。
もしあなたのサービスに「マンツーマン指導」がない場合、AIが勝手に「マンツーマン指導もあります」と捏造してしまうリスクがあります。これを防ぐために、あえて否定表現を使います。
- NG(曖昧): 「動画教材で自分のペースで学べます。」
- OK(明確): 「動画教材による自習形式です。講師によるマンツーマン指導はありません。」
このように明記することで、AIのデータベースの中に「マンツーマン指導=False(なし)」というフラグが立ち、ハルシネーションの発生確率を下げることができます。
よくある誤解を先回りして否定するFAQ
否定表現を自然に盛り込むには、FAQ(よくある質問)セクションを活用するのがベストです。ユーザーが誤解しそうなポイントを先回りして質問にし、回答の中で明確に否定します。
【効果的なFAQの例】
- Q. 無料プランはありますか?
A. いいえ、当サービスに無料プランはございません。すべての機能をご利用いただける有料プランのみの提供となります。 - Q. 解約時に違約金はかかりますか?
A. いいえ、違約金や解約手数料は一切かかりません。いつでもWeb上から解約可能です。
このように「いいえ(No)」から始まる回答を用意することは、AIにとって非常に分かりやすいシグナルとなります。SGEの回答生成AIは、これらのFAQを読み込み、「ユーザーへの回答」としてそのまま引用する傾向があるため、正しい情報をユーザーに届けるための防波堤として機能します。
5. AIが誤解しないシンプルな文構造
最後に、文章の書き方そのものについて解説します。AIは高度な言語処理能力を持っていますが、それでも複雑に入り組んだ文章や、主語が省略された文章を読み解くのは苦手です。AIに正しく内容を理解してもらうためには、「誰が読んでも誤読しようがないシンプルな文構造」を心がける必要があります。
これは「小学生にもわかるように書く」というWebライティングの基本と同じですが、対AIにおいては特に「係り受け(どの言葉がどの言葉にかかっているか)」の明確さが求められます。
AIは「複雑な構文」で読み間違える
以下の例文を見てください。
「弊社は、業界No.1のシェアを誇るA社とは異なり、低価格での提供を実現していますが、サポート体制においてはA社に引けを取らないと自負しており、多くの顧客から支持されています。」
この文章は、人間ならなんとか理解できますが、AIにとっては「業界No.1のシェア」が「弊社」にかかっているのか「A社」にかかっているのか、文脈判断に負荷がかかります。最悪の場合、AIは「弊社は業界No.1のシェアを誇っています」という誤った要約をしてしまう可能性があります。
一文一義(ワンセンテンス・ワンメッセージ)の徹底
AIの誤読を防ぐ黄金ルールは、「一文一義」です。一つの文には一つの情報だけを入れます。先ほどの例文をリライトしてみましょう。
「弊社は低価格でのサービス提供を実現しています。業界シェアNo.1のA社とは異なります。しかし、サポート体制はA社と同等の品質です。その結果、多くのお客様から支持されています。」
このように文章を短く切り、接続助詞(〜が、〜ので)を減らすことで、AIは「主語」と「述語」の関係を正確に把握できます。「弊社=低価格」「弊社≠シェアNo.1」「弊社サポート=高品質」という事実関係がクリアになり、ハルシネーションのリスクが激減します。
主語と述語を近づけるライティング術
日本語は主語を省略しがちですが、AI対策としては「くどいほど主語を明記する」くらいが丁度いいです。
- NG: 「非常に便利で、使いやすいと評判です。」(主語がない)
- OK: 「当社のアプリは非常に便利です。この機能は使いやすいと評判です。」
特に、複数の商品やプランを比較するページでは、主語の省略は致命的です。AIが「プランAの特徴」を「プランBの特徴」だと勘違いしてしまうからです。「プランAは〜です。一方、プランBは〜です。」と、常に主語を明確にすることで、AIに正しい知識をインプットさせましょう。
6. 事実関係のソース(出典)を明記する
AIが回答を生成する際、最も重視するのは「根拠(エビデンス)」です。人間でも、噂話よりも「〇〇新聞によると」という話を信用するように、AIも情報源が明確に示されているテキストを「信頼度の高い事実(High-confidence Fact)」として処理します。
自社の主張がAIに採用されるためには、単に「当社の製品は高性能です」と書くだけでは不十分です。「なぜそう言えるのか?」というソースを明記することで、ハルシネーション(根拠のない嘘)の発生を防ぎ、正しい情報としての採用率を高めることができます。
「〜によると」構文の活用
記事を書く際、意識的に使っていただきたいのが「出典明示の構文」です。外部の権威あるデータや、自社の公開している調査データを引用する場合、文脈の中でその関係性を明確にします。
- 公的機関のデータを引用する場合:
「厚生労働省の令和5年版調査によると、〇〇の傾向が見られます。」
→ AIは「厚生労働省」という強いエンティティと情報を結びつけ、事実として確定させます。 - 自社データを引用する場合:
「2023年10月に実施した社内実測テストの結果に基づくと、従来比で2倍の速度が出ています(別紙データ参照)。」
→ 単なる宣伝文句ではなく、「実測データに基づく事実」として認識させます。
発リンク(Outbound Link)は信頼の証
「外部サイトにリンクを貼るとSEO評価が下がる(ジュースが流出する)」という古い迷信を信じて、頑なにリンクを貼らないサイト運営者がいます。しかし、SGE対策においては逆効果です。
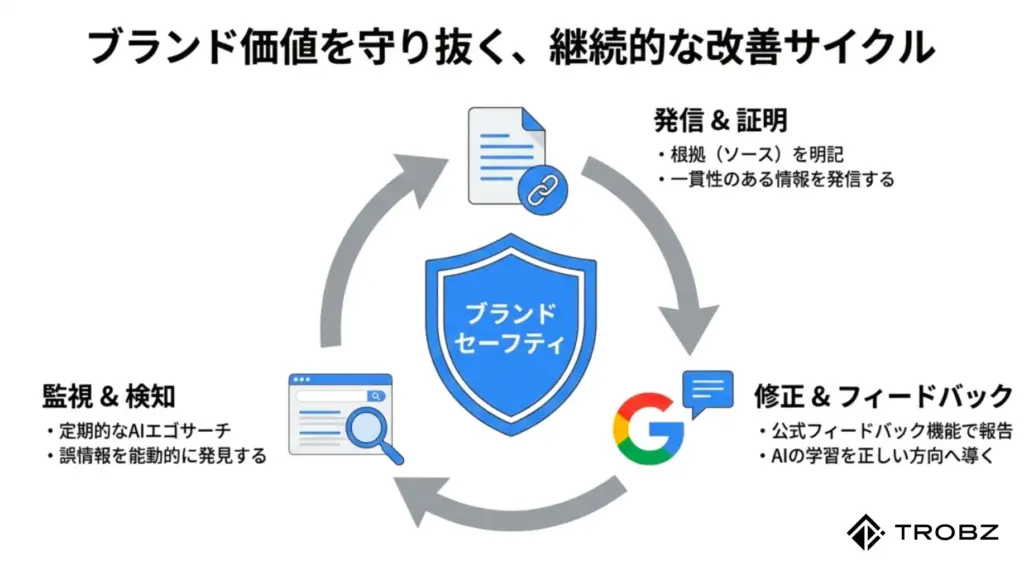
適切な発リンクは、記事の透明性と信頼性を担保する重要なシグナルです。特に、自社の主張を裏付ける公的な情報源や、パートナー企業の公式サイトへのリンクは積極的に設置すべきです。
AIはウェブ上の「引用ネットワーク」を見ています。「どこから来た情報なのか」を隠さずに明示すること、それが結果として「このサイトは嘘をつかない正直な情報源だ」という評価につながるのです。
7. Googleへのフィードバック送信
どれだけ対策をしても、AIが誤った情報を生成してしまうことはあります。そんな時、指をくわえて見ている必要はありません。Googleや各AIプラットフォームに対して、能動的に「間違いを報告する」という手段が用意されています。
これは地味な作業に見えますが、SGEのアルゴリズムはユーザーからのフィードバック(RLHF:Reinforcement Learning from Human Feedback)を学習データとして重視しています。企業公式からの修正依頼は、AIのモデル修正に直結する有効なアクションです。
SGEの回答に対するフィードバック手順
SGEの検索結果画面には、AI生成回答の右下や下部に「フィードバック」や「もっと見る(︙)」ボタンが設置されています。ここから報告を行う際のポイントは、感情的にクレームを入れるのではなく、「なぜ間違っているのか」を論理的に説明することです。
- 具体的な箇所を指摘する:
「全体的に間違っている」ではなく、「2行目の『料金は無料』という記述は誤りです」とピンポイントで指定します。 - 正しい情報源(URL)を添える:
「正しくは有料です。根拠となる公式料金表のURLはこちらです(https://…)」と、AIが参照すべき正しいソースを提示します。
ナレッジパネルの認証と修正提案
AIは検索結果の右側に表示される「ナレッジパネル(企業や人物の概要情報)」を情報のベースとして利用することが多いです。もしここに誤りがあると、AIの回答すべてが間違った前提に基づいて生成されてしまいます。
企業オーナーであれば、ナレッジパネルの「認証(オーナー確認)」を必ず行ってください。認証済みのアカウントから情報の修正を提案すると、Google側で優先的に処理され、反映されるスピードが格段に上がります。
- Googleビジネスプロフィール: 店舗や拠点の情報(住所、営業時間、電話番号)を管理。
- Google Search Console: サイト全体の所有権を確認し、構造化データのエラー状況を監視。
フィードバックは一度送って終わりではありません。AIの学習が反映されるまでには時間がかかるため、誤情報が消えるまで定期的にチェックし、報告を続ける粘り強さが必要です。これはブランドを守るための「デジタル自警団」としての活動といえます。
8. ブランドセーフティの確保
ハルシネーション対策は、単なる情報の正確性の問題を超えて、企業の「ブランドセーフティ(安全性・信頼性の保護)」という経営課題として捉えるべきです。
AIが「この商品は危険だ」「この会社は倒産した」といった深刻な嘘をついた場合、広告を出稿している企業であればブランド毀損に直結しますし、採用活動や株価にも影響を及ぼしかねません。SGE時代におけるブランド管理は、従来の風評被害対策とは異なるアプローチが求められます。
「文脈」をコントロールする
AIは文脈(コンテキスト)に強く影響されます。例えば、あなたの会社名が「詐欺」や「炎上」といったネガティブな単語と一緒に語られているWebページが多いと、AIはその会社に対してネガティブなバイアスを持って学習してしまいます。
これを防ぐためには、自社がコントロールできるメディア(オウンドメディア、SNS、プレスリリース)で、常にポジティブで正確な文脈を発信し続ける必要があります。これを「情報の占有率(Share of Voice)」を高めると言います。
一貫性(Consistency)が信頼を作る
ブランドセーフティの鍵は「一貫性」です。公式サイトでは「A」と言っているのに、Twitter(X)では「B」と言っていて、プレスリリースでは「C」と言っている。このような状態はAIを混乱させ、ハルシネーションの温床となります。
特に、価格改定やサービス終了などの重要な変更があった際は、すべてのチャネルで情報を同時に更新することを徹底してください。Web上のどこを見ても同じ情報が載っている状態を作ることが、AIに「これが揺るぎない真実だ」と確信させるための唯一の方法です。
9. 定期的な自社名検索によるチェック
「エゴサーチ(自社名検索)」は、もはやナルシシズムではなく、必須のリスク管理業務です。しかし、SGE時代のチェック方法は、従来のGoogle検索とは少し異なります。
AIの回答はユーザーごとにパーソナライズ(個人化)される場合があるため、自分のPCで検索した結果が、お客様に見えている結果と同じとは限りません。また、検索するキーワード(クエリ)の言い回しによって、AIが嘘をつくかどうかが変わることもあります。
多角的な「AIエゴサーチ」の手法
私はクライアントに対し、週に一度は以下のパターンでSGEの表示状況をチェックすることを推奨しています。
- シークレットモードでの検索:
個人の閲覧履歴の影響を排除し、フラットな状態でAIがどう回答するかを確認します。 - 「とは」「評判」「料金」の3点セット:
「(自社名)とは」「(自社名) 評判」「(自社名) 料金」という、ユーザーが最も知りたがる3つのクエリで検索し、AI概要の内容に誤りがないか精査します。 - 競合他社との比較クエリ:
「(自社名)と(競合名) どっちがいい?」と検索してみます。ここでAIが自社の特徴を正しく理解し、公平に比較しているかを確認します。もし自社のスペックだけ低く見積もられていたら、即座に公式サイトの比較ページを強化する必要があります。
アラート機能の活用
手動チェックには限界があるため、ツールも活用しましょう。「Googleアラート」に自社名や商品名を登録しておけば、Web上に新しい記事が出たときに通知が来ます。AIは最新の記事を学習データとして取り込むため、ネガティブな記事や誤情報を含む記事がインデックスされた瞬間に検知し、対策を打つことができます。
また、ソーシャルリスニングツールを使って、SNS上で自社に関する誤った噂が拡散されていないかも監視します。AIはSNSのトレンド情報も(リアルタイム性は低いものの)学習ソースとする場合があるため、火種は小さいうちに消し止めることが、結果としてSGEの健全性を保つことにつながります。
10. 正しい情報をAIに学習させる努力
SGE対策のゴールは、AIをコントロールすることではなく、AIと「共創」することです。AIは常に新しい情報を求めています。私たちが質の高い、正確で、構造化された情報を提供し続ければ、AIはそれを喜び、優先的に学習してくれます。
ハルシネーション対策は、一度やれば終わりの対症療法ではありません。Webという広大な海の中で、自社の情報が常にピカピカに磨かれた状態を維持し続ける、終わりのないメンテナンス作業です。
外部プラットフォームの情報を整備する
AIは公式サイトだけでなく、Wikipedia、求人サイト、レビューサイト、業界地図などの「第三者メディア」の情報も信頼します。公式サイトは完璧でも、Wikipediaの情報が10年前のまま止まっていたら、AIはそちらを「客観的な事実」として採用してしまうかもしれません。
- Wikipediaの編集:
もし自社の記事があるなら、事実誤認がないか確認し、必要であれば出典を明記した上で修正を提案します(※Wikipediaは宣伝の場ではないため、客観的な事実のみを記述するルール厳守)。 - 採用サイトやデータベース:
「Wantedly」や「Crunchbase」などの企業データベースの情報も最新に保ちます。これらは構造化データが整っていることが多く、AIが参照しやすい情報源です。
「AIへの手紙」を書き続ける
記事を書くとき、コードを書くとき、常に「これをAIが読んだらどう解釈するだろう?」と想像してください。主語を省かない、結論を先に言う、数字を明確にする、出典を示す。これらはすべて、AIに対する親切心であり、誤解を防ぐための手紙です。
AIは私たちの敵ではありません。正しい情報を学習させれば、24時間365日、文句も言わずに自社の魅力を世界中に宣伝してくれる、最強の広報担当者になり得ます。「嘘をつかせない」のではなく、「真実を語らせる」。そのための努力を、今日から積み重ねていきましょう。
正確な情報発信こそが、最強のAI防衛策となる
本記事では、SGE(生成AI検索)における「ハルシネーション(AIの嘘)」のリスクと、それを防ぐための具体的な対策について解説してきました。
AIが生成する誤情報は、悪意によるものではなく、Web上の「情報の曖昧さ」や「データの汚れ」に起因します。私たち情報発信者がすべきことは、AIの誤りを嘆くことではなく、AIが迷わずに正解にたどり着けるよう、公式サイトを整備し、情報を構造化し、明確な言葉で語ることです。
読者の皆さんが明日から始めるべきアクションは、以下の2つです。
- シークレットモードで「自社名」を検索し、AI概要を精査する:
まずは現状を知ってください。もし誤った情報が表示されていたら、その画面から「フィードバック」を送信し、正しい情報源(URL)を伝えましょう。 - FAQページに「否定表現」を加える:
「無料プランはありますか? → いいえ、ありません」といった、誤解されやすいポイントを明確に否定するQ&Aを追加してください。これがAIの暴走を止めるストッパーになります。
正しい情報を発信し続ける誠実さは、人間だけでなく、AIにも必ず伝わります。あなたのブランドを正確に世界へ届けるために、データハイジーン(情報の清潔さ)を保ち続けてください。
SGEとハルシネーションに関するよくある質問
A. 基本的には「フィードバック」機能での修正依頼となります。
通常の検索結果のような削除申請フォームはSGEにはありません。回答枠のメニューからフィードバックを送り、正しい情報を学習させることで修正を促します。深刻な権利侵害や誹謗中傷が含まれる場合は、Googleの法的な削除リクエストを利用してください。
A. 「絶対」ではありませんが、確率は極めて高くなります。
AIは構造化データを「最も信頼できるシグナル」の一つとして扱いますが、他のサイトでの言及数や文脈も総合して判断します。構造化データは必須ですが、それと同時にWeb全体の情報を管理する姿勢が重要です。
A. はい、情報が少ないサイトほどリスクが高まります。
知名度が低い企業や情報は、AIの学習データが少ないため、AIが推測(幻覚)で穴埋めしようとする傾向があります。情報量が少ないからこそ、公式サイトで正確な定義を発信しておく必要があります。
A. はい、学習データや参照元が異なるため、結果も異なります。
SGEはGoogleの検索インデックスをリアルタイムで参照しますが、ChatGPT(特に無料版)は過去の学習データに基づく傾向があります。両方のプラットフォームでチェックすることをお勧めします。

執筆者
畔栁 洋志
株式会社TROBZ 代表取締役
愛知県岡崎市出身。大学卒業後、タイ・バンコクに渡り日本人学校で3年間従事。帰国後はデジタルマーケティングのベンチャー企業に参画し、新規部署の立ち上げや事業開発に携わる。2024年に株式会社TROBZを創業しLocina MEOやフォーカスSEOをリリース。SEO検定1級保有



NEXT
SERVICE
サービス